Solr
1. Solr简介
前言
- 学习Solr需要一些和java相关的储备知识,在此之前,假设您已经:
- 拥有 Java 开发环境以及相应 IDE(eclipse idea)
- 熟悉 Spring Boot
- 熟悉 Maven
- 熟悉 Lucene
1.1 Solr是什么
- Solr是Apache旗下基于Lucene开发的全文检索的服务。用户可以通过http请求,向Solr服务器提交一定格式的数据(XML,JSON),完成索引库的索引。也可以通过Http请求查询索引库获取返回结果(XML,JSON)。
- Solr和Lucene的区别
- Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
- Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
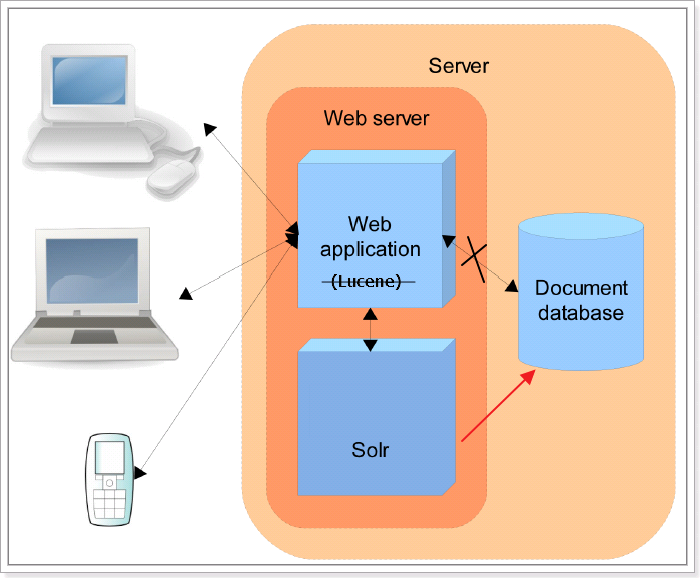
1.2 Solr的发展历程
- 2004年,CNET NetWorks公司的Yonik Seeley工程师为公司网站开发搜索功能时完成了Solr的雏形。起初Solr知识CNET公司的内部项目。
- 2006 年1月,CNET公司决定将Solr源码捐赠给Apache软件基金会。
- 2008 年9月,Solr1.3发布了新功能,其他包括分布式搜索和性能增强等功能。
- 2009 年11月,Solr1.4版本发布,此版本对索引,搜索,Facet等方面进行优化,提高了对PDF,HTML等富文本文件处理能力,还推出了许多额外的插件;
- 2010 年3月,Lucene和Solr项目合并,自此,Solr称为了Lucene的子项目,产品现在由双方的参与者共同开发。
- 2011年,Solr改变了版本编号方案,以便与Lucene匹配。为了使Solr和Lucene有相同的版本号,Solr1.4下一版的版本变为3.1。
- 2012年10月,Solr4.0版本发布,新功能Solr Cloud也随之发布。
- 目前Solr最新版本8.4.1
1.3 Solr的功能优势
- 灵活的查询语法;
- 支持各种格式文件(Word,PDF)导入索引库;
- 支持数据库数据导入索引库;
- 分页查询和排序
- Facet维度查询;
- 自动完成功能;
- 拼写检查;
- 搜索关键字高亮显示;
- Geo地理位置查询;
- Group 分组查询;
- Solr Cloud;
2. 下载和安装
2.1 下载
- solr的下载地址:https://lucene.apache.org/solr/downloads.html
- Solr最新版本是8.4.1的版本,由于8属于比较新的版本,可能有一些未知的Bug,出现问题后可能不好解决,所以我们使用Solr7.
- 因为Solr是基于java语言开发,且Solr7.x要求的JDK版本最少是JDK8.所以我们在安装solr之前,首先必须安装JDK。

2.2 Solr学习资源
- 为了方便学习,Solr官方也提供了很多学习资料。可以在官方的Resources中查看;

- 官方提供的4种资料:
- Solr Quick Start(即Solr快速上手教程);

- Solr官方使用指南。

- Solr官方Wiki

- Solr相关的英文书籍,如solr in action ,solr cookbook.
- 只不过这些资料都是英文资料。对于英文好的同学来说可以参考。对于英文不好的同学来说,直接参考我们的视频教程即可。
2.3 Window下安装Solr
- window系统是我们平时开发和学习使用的一个平台,我们首先先来学习如何在window系统中安装Solr;
2.3.1 运行环境
- solr 需要运行在一个Servlet容器中,Solr7.x 要求jdk最少使用1.8以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器,环境如下:
- Solr:Solr7.x
- Jdk:jdk1.8
- Tomcat:tomcat8.5
2.3.2 安装步骤
下载solr-7.zip并解压;
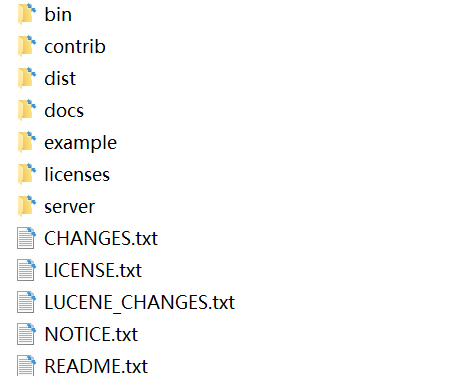
- bin:官方提供的一些solr的运行脚本。
- contrib:社区的一些贡献软件/插件,用于增强solr的功能。
- dist:Solr的核心JAR包和扩展JAR包
- docs:solr的API文档
- example:官方提供的一些solr的demo代码
- licenses:solr遵守的一些开源协议文件
- server:这个目录有点意思,取名为sever,有点迷惑人,其实就是一个jetty.官方为了方便部署Solr,在安装包中内置了一个Jetty; 我们直接就可以利用内置的jetty部署solr;
server/solr-webapp/webapp: 进入到sever目录中有一个webapp的目录,这个目录下部署的就是solr的war包(solr的服务);
接下来我们先来给大家简单演示一下如何使用内置jetty服务器,部署solr服务;
- 进入bin目录
- 启动命令:
solr start
- 关闭命令:
solr stop -all
- 重启solr
solr restart –p p_num - 使用localhost:8983就可以访问solr后台管理系统;
在实际开发中通常我们需要将solr部署到tomcat服务器中;接下来我们要讲解的就是如何将solr部署到tomcat;
- 部署solr到tomcat;
- 解压一个新的tomcat
- 将安装包下
server/solr-webapp/webapp下的solr服务打war包;
- 进入
server/solr-webapp/webapp目录 - 使用cmd窗口bat
jar cvf solr.war ./*
- 将solr.war复制到tomcat/webapps目录中;
- 启动tomcat,解压war包;
- 修改webapp/solr/WEB-INF/web.xml的配置solr_home的位置;
xml<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>“你的solrhome位置”</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>- Solr home目录,SolrHome是Solr运行的主目录,将来solr产生的数据就存储在SolrHOME中;
- SolrHOME可以含多个SolrCore;
- SolrCore即Solr实例每个SolrCore可以对外单独提供全文检索的服务.
- 理解为关系型数据库中的数据库. 关于solrCore的创建我们在后面的课程中专门来讲解;
- 取消安全配置
xml<!-- <security-constraint> <web-resource-collection> <web-resource-name>Disable TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method>TRACE</http-method> </web-resource-collection> <auth-constraint/> </security-constraint> <security-constraint> <web-resource-collection> <web-resource-name>Enable everything but TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method-omission>TRACE</http-method-omission> </web-resource-collection> </security-constraint> -->- 将solr-7.7.2/server/solr中所有的文件复制到solrHome
- 拷贝日志工具相关jar包:将solr-7.7.2/server/lib/ext下的jar包拷贝至上面Tomcat下Solr的/WEB-INF/lib/目录下
- 拷贝metrics相关jar包:将solr-7.7.2/server/lib下metrics相关jar包也拷贝至/WEB-INF/lib/目录下
- 拷贝dataimport相关jar包:solr-7.7.2/dist下dataimport相关jar包也拷贝至/WEB-INF/lib/目录下
- 拷贝log4j2配置文件:将solr-7.7.2/server/resources目录中的log4j配置文件拷入web工程目录WEB-INF/classes(自行创建目录) ,并且修改日志文件的路径
- 重启tomcat,看到welcome,说明solr就安装完毕

- 访问后台管理系统进行测试
http://localhost:8080/solr/index.html
- 在tomcat的bin\catalina.bat中配置日志文件的环境参数bat
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=C:\webapps\fooFts\logs"
- 部署solr到tomcat;
2.4 Linux下安装Solr
在实际的生产环境中,通常我们都需要将solr安装到linux服务器中;由于我们目前属于学习阶段。我们就使用虚拟机来模拟一个Linux服务器安装solr;
环境准备:
- Cent0S 7.0 linux系统;
- Jdk1.8 linux安装包
- tomcat:tomcat8.5
- solr7.x 安装包
将linux中相关的安装包上传到linux
- sftp上传 Jdk1.8 tomcat8.5 solr7.x 安装包到linux;
- 使用CRT连接到Linux
- alt+p打开sftp,上传相关的软件安装到到linux

- sftp上传 Jdk1.8 tomcat8.5 solr7.x 安装包到linux;
安装jdk

- 解压jdk
battar -xzvf jdk18 -C /usr/local 2. 配置环境变量bat
2. 配置环境变量batvi /etc/profile export JAVA_HOME=/usr/local/jdk1.8.0_171 export PATH=$JAVA_HOME/bin:$PATH- 重新加载profile文件,让配置文件生效;

- 测试bat
java -version
安装tomcat,tomcat的安装比较简单,只需要解压即可;

安装solr,安装solr的过程和windows系统过程完全相同。只不过通过linux命令来操作而已;
- 解压solr安装包,直接解压在宿主目录即可; 解压的目录结构和window版的目录结构相同;
- 解压solr安装包,直接解压在宿主目录即可; 解压的目录结构和window版的目录结构相同;
- 将server/solr-webapp/webapp下的solr服务打war包;
- 2.1 进入到webapp目录
cd server/solr-webapp/webapp - 2.2 将webapp中的代码打成war包
jar -cvf solr.war ./*
- 将war包部署到tomcat的webapps目录

- 将war包部署到tomcat的webapps目录
- 启动tomcat,解压solr.war
- 4.1 进入到tomcat的bin目录bat
cd /usr/local/apache-tomcat-8.5.50 - 4.2 启动tomcat

- 4.3 进入到webapp目录中查看
- 修改webapp/solr/WEB-INF/web.xml的配置solrhome的位置;
xml<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>“你的solrhome位置”</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>- 既然solrhome指定的位置在/user/local/solr_home下面;所以需要创建一个solr_home的文件夹;

- 取消安全配置(和window相同)
- 将solr-7.7.2/server/solr中所有的文件复制到solrHome
- 7.1 进入到solr-7.7.2/server/solr

- 7.2 将所有的文件复制到solrHome

- 拷贝日志工具相关jar包:将solr-7.7.2/server/lib/ext下的jar包拷贝至上面Tomcat下Solr的/WEB-INF/lib/目录下
- 8.1 进入solr-7.7.2/server/lib/extbat
cd solr-7.7.2/server/lib/ext - 8.2 将所有文件复制到Tomcat下Solr的/WEB-INF/lib/

- 拷贝 metrics相关jar包:将solr-7.7.2/server/lib下metrics相关jar包也拷贝至/WEB-INF/lib/目录下
- 9.1 进入solr-7.7.2/server/libbat
cd solr-7.7.2/server/lib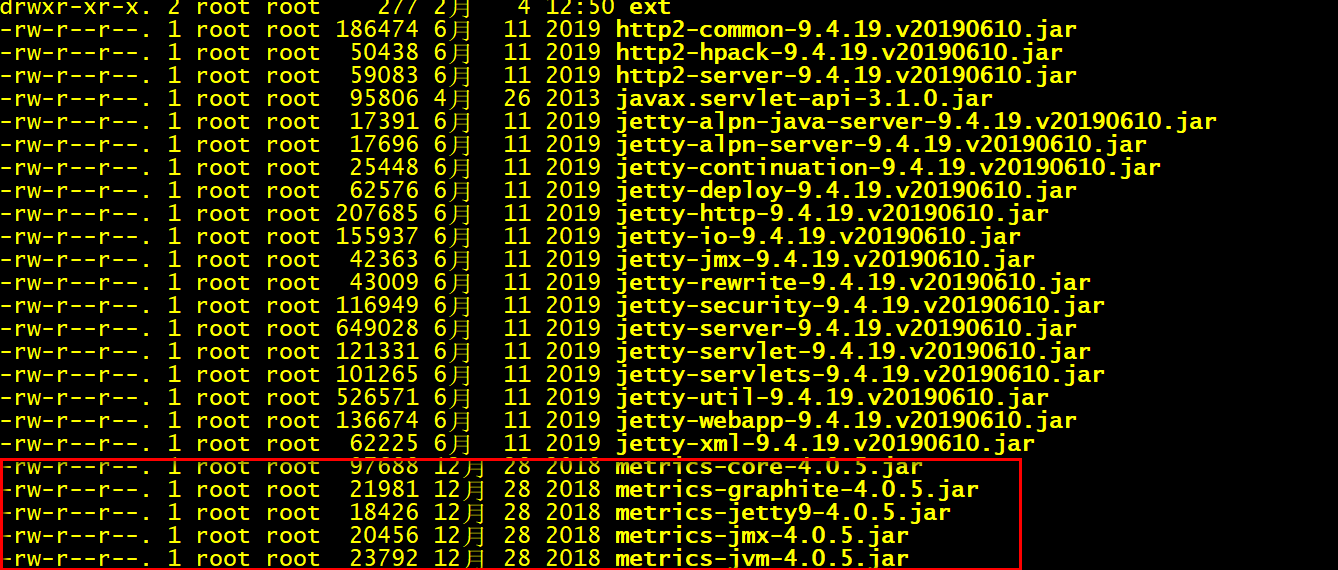
- 9.2 将metrics-开始的所有文件复制到Tomcat下Solr的/WEB-INF/lib/

- 将solr安装包中dist目录中和数据导入相关的2个包,复制到tomcat/webapps/solr/WEB-INF/lib
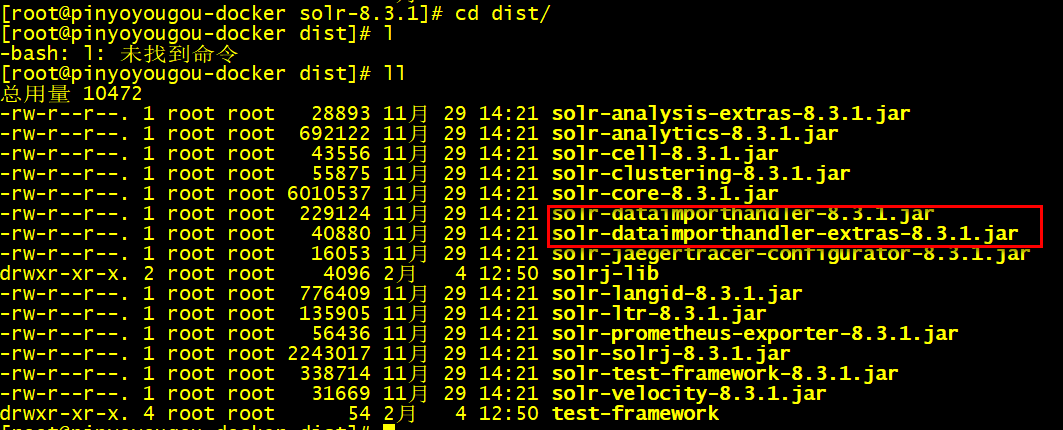
batcp solr-dataimporthandler-* /usr/local/apache-tomcat-8.5.50/webapps/solr/WEB-INF/lib/- 将solr安装包中dist目录中和数据导入相关的2个包,复制到tomcat/webapps/solr/WEB-INF/lib
- 拷贝log4j2配置文件:将solr-7.7.2/server/resource目录中的log4j配置文件拷入web工程目录WEB-INF/classes(自行创建目录) ,并且修改日志文件的路径
- 10.1 进入到solr-7.7.2/server/resource目录中
batcd solr-7.7.2/server/resource
- 10.2 将log4j2的配置文件复制到solr 的WEB-INF/classes目录;
- 创建classes目录

- log4j的文件复制;

- 创建classes目录
- 重启tomcat
- 进入到日志文件中查看启动情况;bat
cd ../logs more catalina.out
- 访问后台管理系统进行测试
3. Solr基础
3.1 SolrCore
- solr部署启动成功之后,需要创建core才可以使用的,才可以使用Solr;类似于我们安装完毕MySQL以后,需要创建数据库一样;
3.1.1 什么是SolrCore
- 在Solr中、每一个Core、代表一个索引库、里面包含索引数据及其配置信息。
- Solr中可以拥有多个Core、也就是可以同时管理多个索引库、就像mysql中可以有多个数据库一样。
- 所以SolrCore可以理解成MySQL中的数据库;
3.1.2 SolrCore维护(windows)
- 简单认识SolrCore以后,接下来要完成的是SolrCore的创建。在创建solrCore之前,我们首先认识一下SolrCore目录结构:
- SolrCore目录结构
- Core中有二个重要目录:conf和data

- conf:存储SolrCore相关的配置文件;
- data:SolrCore的索引数据;
- core.properties:SolrCore的名称,name=SolrCore名称;
- 所以搭建一个SolrCore只需要创建 2个目录和一个properties文件即可;
- Core中有二个重要目录:conf和data
- SolrHome中搭建SolrCore
- 2.1 solrCore的目录结构搞清楚以后,接下来就是关于SolrCore在哪里进行创建呢?
- 在之前搭建Solr的时候,我们说一个solr_home是由多个solrCore构成,所以solrCore是搭建在solrHome中;
- 在之前搭建Solr的时候,我们说一个solr_home是由多个solrCore构成,所以solrCore是搭建在solrHome中;
- 2.2 将solr安装包中的配置文件复制到conf目录;
- 搭建好solrCore以后,conf目录还没没有配置文件,我们需要将solr安装包中提供的示例配置文件复制到conf目录
- solr安装包中配置文件的位置:solr-7.7.2\example\example-DIH\solr\solr\conf
- 2.3 重启solr
- 2.4 在solr的管理后台来查看
- 如何创建多个solrCore;
- 只需要复制SolrCore一份,重启solr;
- SolrCore目录结构
3.1.3 SolrCore维护(linux)
进入到SolrHome
batcd /usr/local/solr_home/
创建SolrCore
mkdir -p collection1/data mkdir -p collection1/conf cd collection1 touch core.properties

将solr安装包中提供的示例配置文件复制到conf目录
batcd solr-8.3.1/example/example-DIH/solr/solr/conf/ cp -r * /usr/local/solr_home/collection1/conf/重启tomcat
访问后台管理系统
3.2 Solr后台管理系统的使用
- 概述
- 上一个章节我们已经学习完毕如何在solr中创建SolrCore。有了SolrCore以后我们就可以进行索引和搜索的操作,在进行索引和搜索操作之前,首先学习一下Solr后台管理系统的使用;
- DashBoard:solr的版本信息、jvm的相关信息还有一些内存信息。
- Logging:日志信息,也有日志级别,刚进入查看的时候肯定是有几个警告(warn)信息的,因为复制solr的时候路径发生了变化导致找不到文件,但是并不影响。
- Core Admin:SolrCore的管理页面。可以使用该管理界面完成SolrCore的卸载。也可以完成SolrCore的添加 能添加的前提,SolrCore在solr_home中目录结构是完整的。
- Java Properties:顾名思义,java的相关配置,比如类路径,文件编码等。
- Thread Dump:solr服务器当前活跃的一些线程的相关信息。
- 以上的5个了解一下就行。
- 当我们选择某一个solrCore以后,又会出现一些菜单,这些菜单就是对选择的SolrCore进行操作的,接下来我们重点要讲解的就是这些菜单的使用;
3.2.1 Documents
- 作用:向SolrCore中添加数据,删除数据,更新数据(索引)。
- 在讲解如何使用Documents菜单向Solr中添加数据之前,我们首先回顾一下我们之前在Lucene中学习的一些概念;
- 概念介绍:
- 文档:document是lucene进行索引创建以及搜索的基本单元,我们要把数据添加到Lucene的索引库中,数据结构就是document,如果我从Lucene的索引库中进行数据的搜索, 搜索出来的结果的数据结构也document;
- 文档的结构:学习过Lucene的同学都知道,一个文档是由多个域(Field)组成,每个域包含了域名和域值;
- 如果数据库进行类比,文档相单于数据库中的一行记录,域(Field)则为一条记录的字段。
- 数据库中记录:

- lucene/solr中文档

- 索引:通常把添加数据这个操作也成为创建索引;
- 搜索:通常把搜索数据这个操作也成为搜索索引;
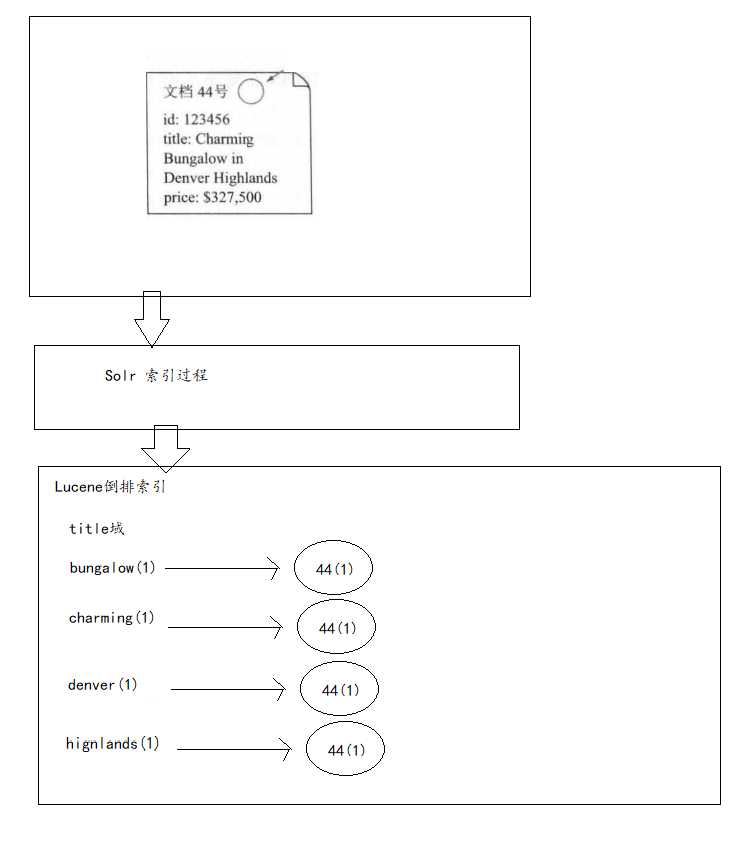
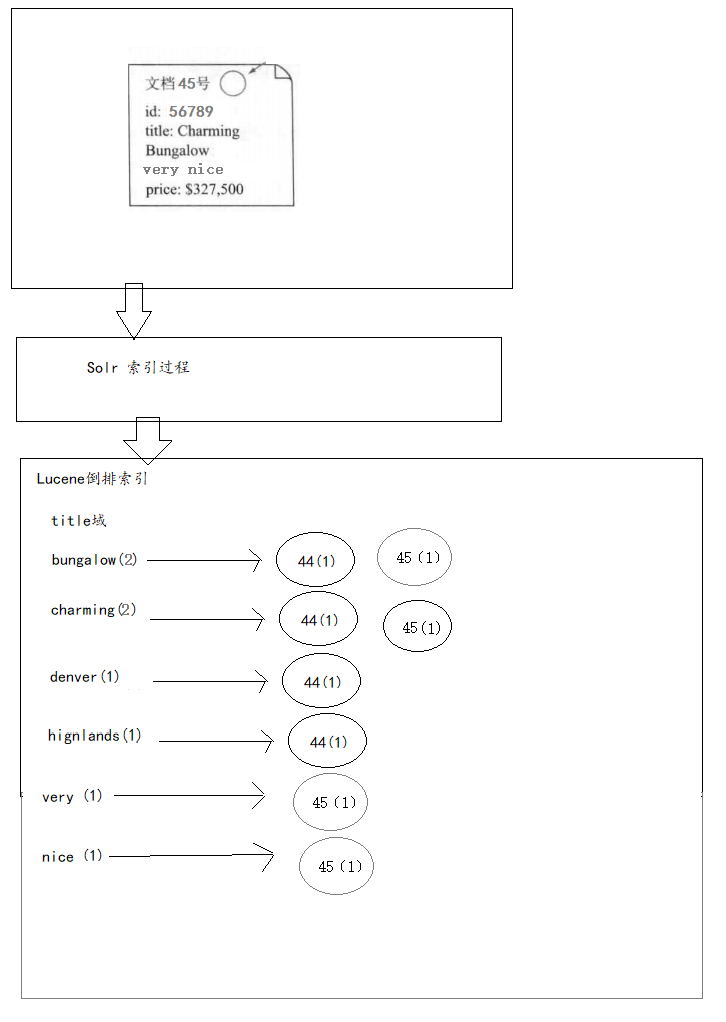
- 倒排索引:
- Solr添加数据的流程:
- Solr添加数据的流程:
- Lucene首先对文档域中的数据进行分词,建立词和文档之间的关系;

- 将来我们就可以根据域中的词,快速查找到对应的文档;
- Lucene中相关概念回顾完毕;
- 添加文档
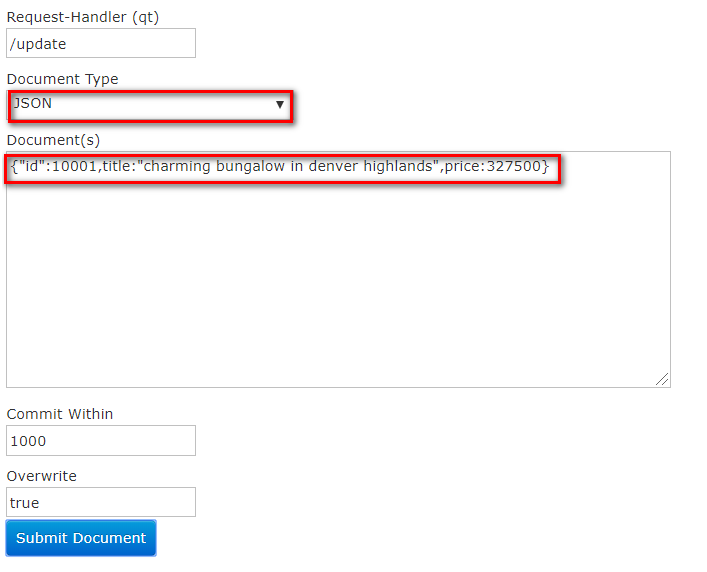
- 使用后台管理系统,向Solr中添加文档。文档的数据格式可以是JSON,也可以XML;
- 以JSON的形式添加文档:
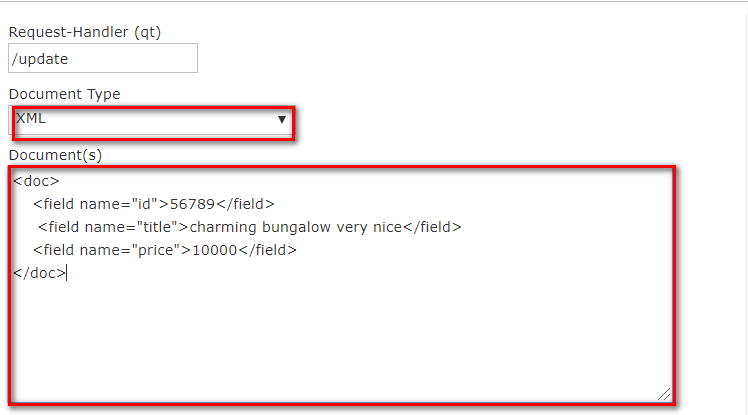
- 以XML的形式添加文档
- 通常我们可以添加一些测试数据;
- 修改数据
- Solr要求每一个文档都需要有一个id域;如果添加的文档id在SolrCore中已经存在,即可完成数据修改;
- 删除数据
- 只能通过XML的格式删除文档;下面我们提供2种删除方式
- 根据id删除xml
<delete> <id>8</id> </delete> <commit/> - 根据条件删除,需要指定查询的字符串,根据查询的字符串删除。查询字符串如何编写,后面详细讲解。xml
<delete> <query>*:*</query> </delete> <commit/>
- 根据id删除
3.2.2 Analyse
- 作用:测试域/域类型(后面讲解)分词效果;
- 之前我们在讲解倒排索引的时候,当我们向Solr中添加一个文档,底层首先要对文档域中的数据进行分词。
- 建立词和文档关系。
- 测试刚才添加文档的域id ,title,name域的分词效果;
- 思考的问题?
- id为什么不分词,name域为什么可以分词?
- name域可以对中文进行分词吗?
- 添加文档的时候,域名可以随便写吗?
- 要想搞清楚这些问题,我们需要学习Solr的配置;
3.2.4 Solr的配置-Field
在Solr中我们需要学习其中4个配置文件;
- SolrHome中solr.xml
- SolrCore/conf中solrconfig.xml
- SolrCore/confSolrCore中managed-schema
- SolrCore/conf/data-config.xml
managed-schema【最常用】
- 在Solr中进行索引时,文档中的域需要提前在managed-schema文件中定义,在这个文件中,solr已经提前定义了一些域,比如我们之前使用的id,price,title域。通过管理界面查看已经定义的域;

- 在Solr中进行索引时,文档中的域需要提前在managed-schema文件中定义,在这个文件中,solr已经提前定义了一些域,比如我们之前使用的id,price,title域。通过管理界面查看已经定义的域;
下面就是solr中一定定义好的一个域,name
xml<field name="name" type="text_general" indexed="true" stored="true"/>field标签:定义一个域;
- name属性:域名
- indexed:是否索引,是否可以根据该域进行搜索;一般哪些域不需要搜索,图片路径。
- stored:是否存储,将来查询的文档中是否包含该域的数据; 商品的描述。
- 举例:将图书的信息存储到Solr中;Description域。indexed设置为true,store设置成false;
- 可以根据商品描述域进行查询,但是查询出来的文档中是不包含description域的数据;

- multiValued:是否多值,该域是否可以存储一个数组; 图片列表;
- required:是否必须创建文档的时候,该域是否必须;id
- type:域类型,决定该域使用的分词器。分词器可以决定该域的分词效果(分词,不分词,是否支持中文分词)。域的类型在使用之前必须提前定义;在solr中已经提供了很多的域类型xml
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <!-- in this example, we will only use synonyms at query time <filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/> <filter class="solr.FlattenGraphFilterFactory"/> --> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType> - 自定义一个商品描述域:xml
<field name="item_description" type="text_general" indexed="true" stored="false"/> - 定义一个图片域xml
<field name="item_image" type="string" indexed="false" stored="true" multiValued=true/> - 重启solr
- 测试分词效果
- 通过测试我们发现text_general域类型,支持英文分词,不支持中文分词;

- 测试定义域
- 测试添加文档json
{"id":"1101","name":"java编程思想","item_image":["big.jpg","small.jpg"],"item_description":"lucene是apache的开源项目,是一个全文检索的工具包。"} - 测试item_description域搜索
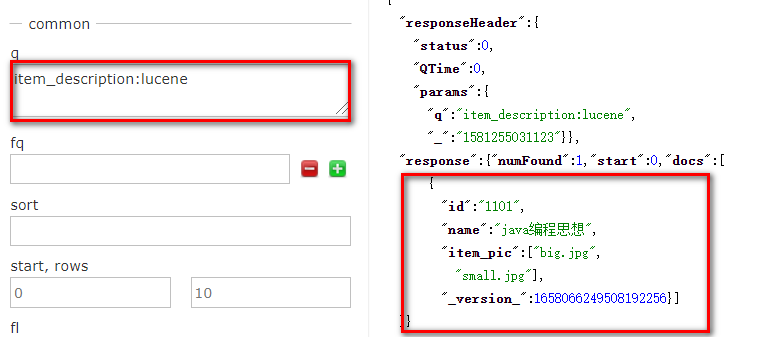
- 通过我们测试,我们发现可以通过item_description域进行搜索,但是搜索结果的文档中是没有item_description域的数据的;
- 测试item_pic域搜索
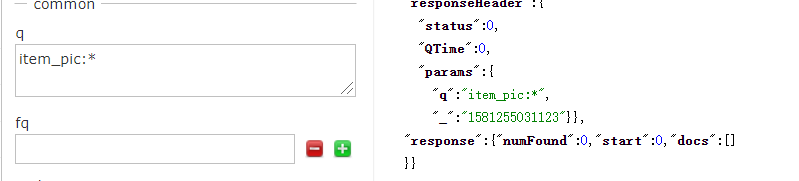
- 通过我们测试,我们发现不能通过item_pic域进行搜索;
- 测试添加文档
3.2.5 Solr的配置-FieldType
- 概述
- 上一章节我们讲解了Field的定义。接下来我们要讲解的是FieldType域类型;
- 刚才我们给大家讲解了如何在schema文件中定义域,接下来我们要讲解域类型如何定义;
- 每个域都需要指定域类型,而且域类型必须提前定义。域类型决定该域使用的索引和搜索的分词器,影响分词效果。
- Solr中已经提供好了一些域类型;
- text_general:支持英文分词,不支持中文分词;
- string:不分词;适合于id,订单号等。
- pfloat:适合小数类型的域,特殊分词,支持大小比较;
- pdate:适合日期类型的域,特殊分词,支持大小比较;
- pint:适合整数类型的域,特殊分词,支持大小比较;
- plong:适合长整数类型的域,特殊分词,支持大小比较;
- 我们以text_general为例看一下如何定义FiledType.text_general是solr中已经提供好的一个域类型;他的定义如下;xml
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <!-- in this example, we will only use synonyms at query time <filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/> <filter class="solr.FlattenGraphFilterFactory"/> --> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType>
3.2.5.1 相关属性
- name(重点)
- 域类型名称,定义域类型的必须指定,并且要唯一
- 将来定义域的时候需要指定通过域名称来指定域类型;
- class(重点)
- 域类型对应的java类,必须指定。
- 如果该类是solr中的内置类,使用solr.类名指定即可。如果该类是第三方的类,需要指定全类名。
- 如果class是TextField,我们还需要使用
<analyzer>子标签来配置分析器;
- positionIncrementGap(了解)
- 用于多值字段,定义多值间的间隔,来阻止假的短语匹配。
- autoGeneratePhraseQueries(了解)
- 用于文本字段,如果设为true,solr会自动对该字段的查询生成短语查询,即使搜索文本没带“”
- enableGraphQueries
- 是否支持图表查询(了解)
- docValuesFormat(了解)
- docValues字段的存储格式化器:schema-aware codec,配置在solrconfig.xml中的
- postingsFormat(了解)
- 词条格式器:schema-aware codec,配置在solrconfig.xml中的
3.2.5.2 Solr自带的FieldType类
- solr除了提供了TextField类,我们也可以查看它提供的其他的FiledType类,我们可以通过官网查看其他的FieldType类的作用:
- http://lucene.apache.org/solr/guide/8_1/field-types-included-with-solr.html
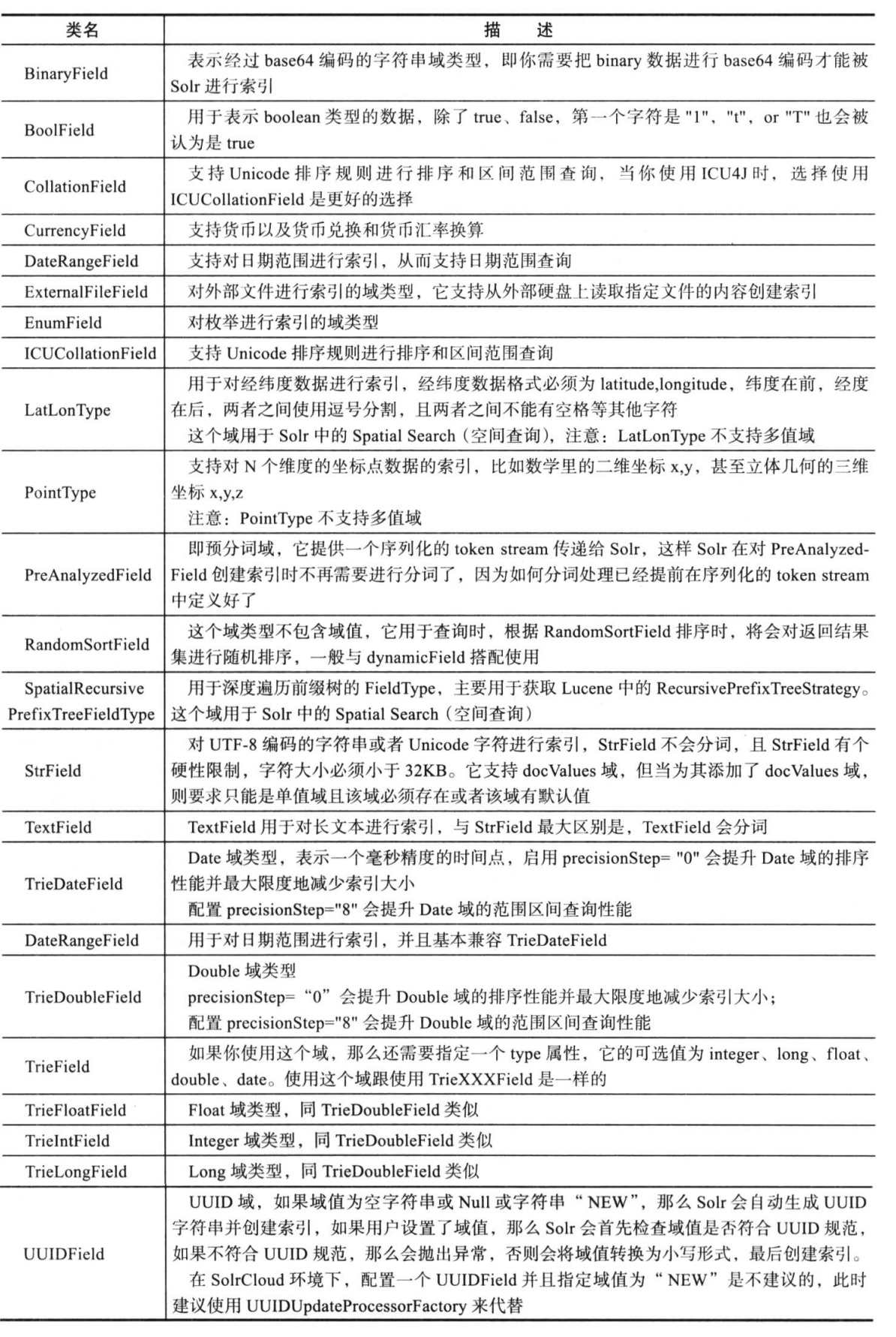
- 以上的FieldType类的使用,我们不会一一进行讲解,只会讲解常用的一部分;
- http://lucene.apache.org/solr/guide/8_1/field-types-included-with-solr.html
3.2.5.3 FieldType常用类的使用
- 首先我们来讲解第一个FieldType类;

- TextField:支持对字符类型的数据进行分词;对于 solr.TextField 域类型,需要为其定义分析器;
分析器的基本概念
- 分析器就是将用户输入的一串文本分割成一个个token,一个个token组成了tokenStream,然后遍历tokenStream对其进行过滤操作,比如去除停用词,特殊字符,标点符号和统一转化成小写的形式等。分词的准确的准确性会直接影响搜索的结果,从某种程度上来讲,分词的算法不同,都会影响返回的结果。因此分析器是搜索的基础;
- 分析器的工作流程:
- 分词
- 过滤
- 在solr中已经为我们提供了很多的分词器及过滤器;
- Solr中提供的分词器tokenizer:http://lucene.apache.org/solr/guide/8_1/tokenizers.html
- 标准分词器,经典分词器,关键字分词器,单词分词器等,不同的分词器分词的效果也不尽相同;

- 标准分词器,经典分词器,关键字分词器,单词分词器等,不同的分词器分词的效果也不尽相同;
- Solr中提供的过滤器tokenfilter:http://lucene.apache.org/solr/guide/8_1/about-filters.html
- 不同的过滤器过滤效果也不同,有些是去除标点符号的,有些是大写转化小写的;
- 不同的过滤器过滤效果也不同,有些是去除标点符号的,有些是大写转化小写的;
- Solr中提供的分词器tokenizer:http://lucene.apache.org/solr/guide/8_1/tokenizers.html
常用分词器的介绍
- Standard Tokenizer
- 作用:这个Tokenizer将文本的空格和标点当做分隔符。注意,你的Email地址(含有@符合)可能会被分解开;用点号(就是小数点)连接的部分不会被分解开。对于有连字符的单词,也会被分解开。
- 例子:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> </analyzer>输入:“Please, email john.doe@foo.com by 03-09, re: m37-xq.” 输出: “Please”, “email”, “john.doe”, “foo.com”, “by”, “03”, “09”, “re”, “m37”, “xq
- Classic Tokenizer
- 作用:基本与Standard Tokenizer相同。注意,用点号(就是小数点)连接的部分不会被分解开;用@号(Email中常用)连接的部分不会被分解开;互联网域名(比如wo.com.cn)不会被分解开;有连字符的单词,如果是数字连接也会被分解开。
- 例子:xml
<analyzer> <tokenizer class="solr.ClassicTokenizerFactory"/> </analyzer>输入: “Please, email john.doe@foo.com by 03-09, re: m37-xq.” 输出: “Please”, “email”, “john.doe@foo.com”, “by”, “03-09”, “re”, “m37-xq”
- Keyword Tokenizer
- 作用:把整个输入文本当做一个整体。
- 例子:xml
<analyzer> <tokenizer class="solr.KeywordTokenizerFactory"/> </analyzer>输入: “Please, email john.doe@foo.com by 03-09, re: m37-xq.” 输出: “Please, email john.doe@foo.com by 03-09, re: m37-xq.”
- Letter Tokenizer
- 作用:只处理字母,其他的符号都被认为是分隔符
- 例子:xml
<analyzer> <tokenizer class="solr.LetterTokenizerFactory"/> </analyzer>输入: “I can’t.” 输出: “I”, “can”, “t”
- Lower Case Tokenizer
- 作用:以非字母元素分隔,将所有的字母转化为小写。
- 例子:xml
<analyzer> <tokenizer class="solr.LowerCaseTokenizerFactory"/> </analyzer>输入: “I just LOVE my iPhone!” 输出: “i”, “just”, “love”, “my”, “iphone”
- N-Gram Tokenizer
- 作用:将输入文本转化成指定范围大小的片段的词,注意,空格也会被当成一个字符处理;
- 参数:
参数 值 说明 minGramSize 整数,默认1 指定最小的片段大小,需大于0 maxGramSize 整数,默认2 指定最大的片段大小,需大于最小值 - 例子1:xml
<analyzer> <tokenizer class="solr.NGramTokenizerFactory"/> </analyzer>输入: “hey man” 输出: “h”, “e”, “y”, ” “, “m”, “a”, “n”, “he”, “ey”, “y “, ” m”, “ma”, “an” - 例子2:xml
<analyzer> <tokenizer class="solr.NGramTokenizerFactory" minGramSize="4" maxGramSize="5"/> </analyzer>输入: “bicycle” 输出: “bicy”, “bicyc”, “icyc”, “icycl”, “cycl”, “cycle”, “ycle“
- Edge N-Gram Tokenizer
作用:用法和N-Gram Tokenizer类似
参数:
参数 值 说明 minGramSize 整数,默认1 指定最小的片段大小,需大于0 maxGramSize 整数,默认1 指定最大的片段大小,需大于或等于最小值 side “front” 或 “back”, 默认”front” 指定从哪个方向进行解析 例子1:
xml<analyzer> <tokenizer class="solr.EdgeNGramTokenizerFactory" /> </analyzer>输入: “babaloo” 输出: “b”例子2:
xml<analyzer> <tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="2" maxGramSize="5"/> </analyzer>输入: “babaloo” 输出: “ba”, “bab”, “baba”, “babal”例子3:
xml<analyzer> <tokenizer class="solr.EdgeNGramTokenizerFactory" minGramSize="2" maxGramSize="5" side="back"/> </analyzer>输入: “babaloo” 输出: “oo”, “loo”, “aloo”, “baloo”
- Regular Expression Pattern Tokenizer
作用:可以指定正则表达式来分析文本。
参数:
参数 值 说明 attern 必选项 正规表达式 roup 数字,可选,默认-1 负数表示用正则表达式做分界符;非正数表示只分析满足正则表达式的部分;0表示满足整个正则表达式;大于0表示满足正则表达式的第几个括号中的部分 例子1:
xml<analyzer> <tokenizer class="solr.PatternTokenizerFactory" pattern="\s*,\s*"/> </analyzer>输入: “fee,fie, foe , fum” 输出: “fee”, “fie”, “foe”, “fum”例子2:
xml<analyzer> <tokenizer class="solr.PatternTokenizerFactory" pattern="[A-Z][A-Za-z]*" group="0"/> </analyzer>输入: “Hello. My name is Inigo Montoya. You killed my father. Prepare to die.” 输出: “Hello”, “My”, “Inigo”, “Montoya”, “You”, “Prepare” 这里的group为0,表示必须满足整个表达式,正则表达式的含义是以大写字母开头,之后是大写字母或小写字母的组合。例子3:
xml<analyzer> <tokenizer class="solr.PatternTokenizerFactory" pattern="(SKU|Part(\sNumber)?):?\s(\[0-9-\]+)" group="3"/> </analyzer>输入: “SKU: 1234, Part Number 5678, Part: 126-987” 输出: “1234”, “5678”, “126-987” 这个group等于3,表示满足第三个括号”[0-9-]+”中的正则表达式
- White Space Tokenizer
- 作用:这个Tokenizer将文本的空格当做分隔符。
- 参数:
参数 值 说明 rule 默认java 如何定义空格 - 例子:xml
<analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory" rule="java" /> </analyzer>输入: “To be, or what?” 输出: “To”, “be,”, “or”, “what?”
- 在这些分词器中,我们最常用的一个分词器。Standard Tokenizer;但也仅仅只能对英文进行分词;
常用过滤器介绍
上一小结我们学习了Solr中的常用分词器,接下来我们讲解过滤器。过滤器是对分词器的分词结果进行再次处理,比如:将词转化为小写,排除掉停用词等。
- Lower Case Filter
- 作用:这个Filter将所有的词中大写字符转化为小写
- 例子:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer>原始文本: “Down With CamelCase” 输入: “Down”, “With”, “CamelCase” 输出: “down”, “with”, “camelcase”
- Length Filter
- 作用:这个Filter处理在给定范围长度的tokens。
- 参数:
参数 值 说明 min 整数,必填 指定最小的token长度 max 整数,必填,需大于min 指定最大的token长度 - 例子:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LengthFilterFactory" min="3" max="7"/> </analyzer>原始文本: “turn right at Albuquerque” 输入: “turn”, “right”, “at”, “Albuquerque” 输出: “turn”, “right”
- pattern Replace Filter
- 作用:这个Filter可以使用正则表达式来替换token的一部分内容,与正则表达式想匹配的被替换,不匹配的不变。
- 参数:
参数 值 说明 pattern 必填,正则表达式 需要匹配的正则表达式 replacement 必填,字符串 需要替换的部分 replace “all” 或 “first”, 默认”all” 全部替换还是,只替换第一个 - 例子1:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog"/> </analyzer>原始文本: “cat concatenate catycat” 输入: “cat”, “concatenate”, “catycat” 输出: “dog”, “condogenate”, “dogydog” - 例子2:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.PatternReplaceFilterFactory" pattern="cat" replacement="dog" replace="first"/> </analyzer>原始文本: “cat concatenate catycat” 输入: “cat”, “concatenate”, “catycat” 输出: “dog”, “condogenate”, “dogycat”
- Stop Words Filter
- 作用:这个Filter会在解析时忽略给定的停词列表(stopwords.txt)中的内容;
- 参数:
参数 值 说明 words 可选,停词列表 指定停词列表的路径 format 可选,如”snowball” 停词列表的格式 ignoreCase 布尔值,默认false 是否忽略大小写 - 例子1:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt"/> </analyzer>txt保留词列表stopwords.txt be or to原始文本: “To be or what?” 输入: “To”(1), “be”(2), “or”(3), “what”(4) 输出: “To”(1), “what”(4) - 例子2:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/> </analyzer>txt保留词列表stopwords.txt be or to原始文本: “To be or what?” 输入: “To”(1), “be”(2), “or”(3), “what”(4) 输出: “what”(4)
- Keep Word Filter
- 作用:这个Filter将不属于列表中的单词过滤掉。和
Stop Words Filter的效果相反。 - 参数
参数 值 说明 words 必填,以.txt结尾的文件 提供保留词列表 ignoreCase 布尔值,默认false 是否忽略保留词列表大小写 - 例子1:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/> </analyzer>txt保留词列表keepwords.txt happy funny silly原始文本: “Happy, sad or funny” 输入: “Happy”, “sad”, “or”, “funny” 输出: “funny” - 例子2:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.KeepWordFilterFactory" words="keepwords.txt" ignoreCase="true" /> </analyzer>保留词列表keepwords.txt happy funny silly原始文本: “Happy, sad or funny” 输入: “Happy”, “sad”, “or”, “funny” 输出: “Happy”, “funny”
- 作用:这个Filter将不属于列表中的单词过滤掉。和
- Synonym Filter
- 作用:这个Filter用来处理同义词;
- 参数:
参数 值 说明 synonyms 必选,以.txt结尾的文件 指定同义词列表 ignoreCase 布尔值,默认false 是否忽略大小写 format 可选,默认solr 指定解析同义词的策略
注意,常用的同义词列表格式: 1. 以#开头的行为注释内容,忽略 2. 以,分隔的文本,为双向同义词,左右内容等价,互为同义词 3. 以=>分隔的文本,为单向同义词,匹配到左边内容,将替换为右边内容,反之不成立- 例子:xml
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="mysynonyms.txt"/> </analyzer>txt同义词列表synonyms.txt couch,sofa,divan teh => the huge,ginormous,humungous => large small => tiny,teeny,weeny原始文本: “teh small couch” 输入: “teh”(1), “small”(2), “couch”(3) 输出: “the”(1), “tiny”(2), “teeny”(2), “weeny”(2), “couch”(3), “sofa”(3), “divan”(3) 原始文本: “teh ginormous, humungous sofa” 输入: “teh”(1), “ginormous”(2), “humungous”(3), “sofa”(4) 输出: “the”(1), “large”(2), “large”(3), “couch”(4), “sofa”(4), “divan”(4)
TextField的使用
- 前面我们已经学习完毕solr中的分词器和过滤器,有了这些知识的储备后,我们就可以使用TextField这种类定义FieldType.
- 之前我们说过,在我们在使用TextField作为FieldType的class的时候,必须指定Analyzer,用一个
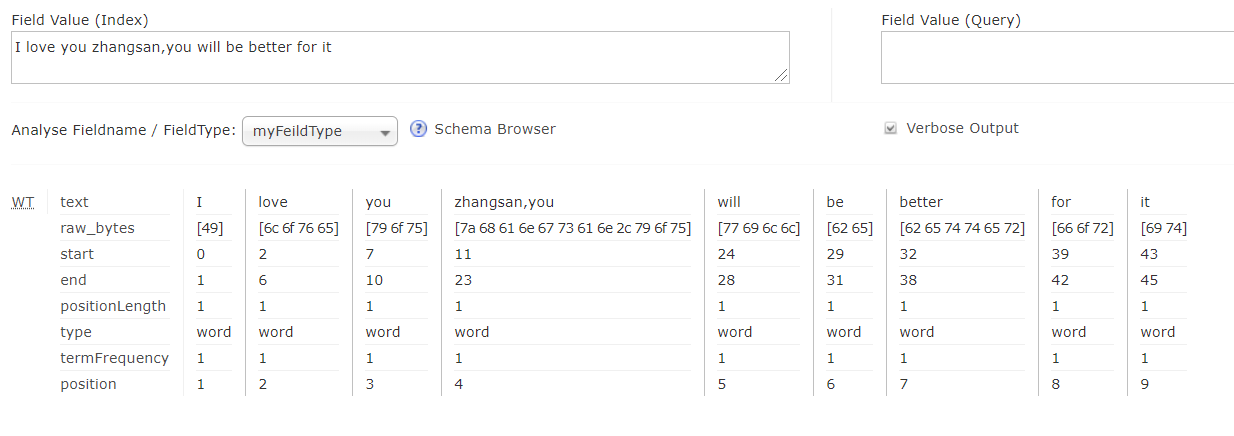
<analyzer>标签来声明一个Analyzer; - 方式一:直接通过class属性指定分析器类,该类必须继承org.apache.lucene.analysis.Analyzerxml
<fieldType name="nametext" class="solr.TextField"> <analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/> </fieldType>- 这里的
WhitespaceAnalyzer就是一种分析器,这个分析器中封装了我们之前讲过了一个分词器WhitespaceTokenizer。 - 这种方式写起来比较简单,但是透明度不够,使用者可能不知道这个分析器中封装了哪些分词器和过滤器
- 测试:
- 对于那些复杂的分析需求,我们也可以在分析器中灵活地组合分词器、过滤器;
- 这里的
- 方式二:可以灵活地组合分词器、过滤器xml
<fieldType name="nametext" class="solr.TextField"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt"/> </analyzer> </fieldType>- 测试:
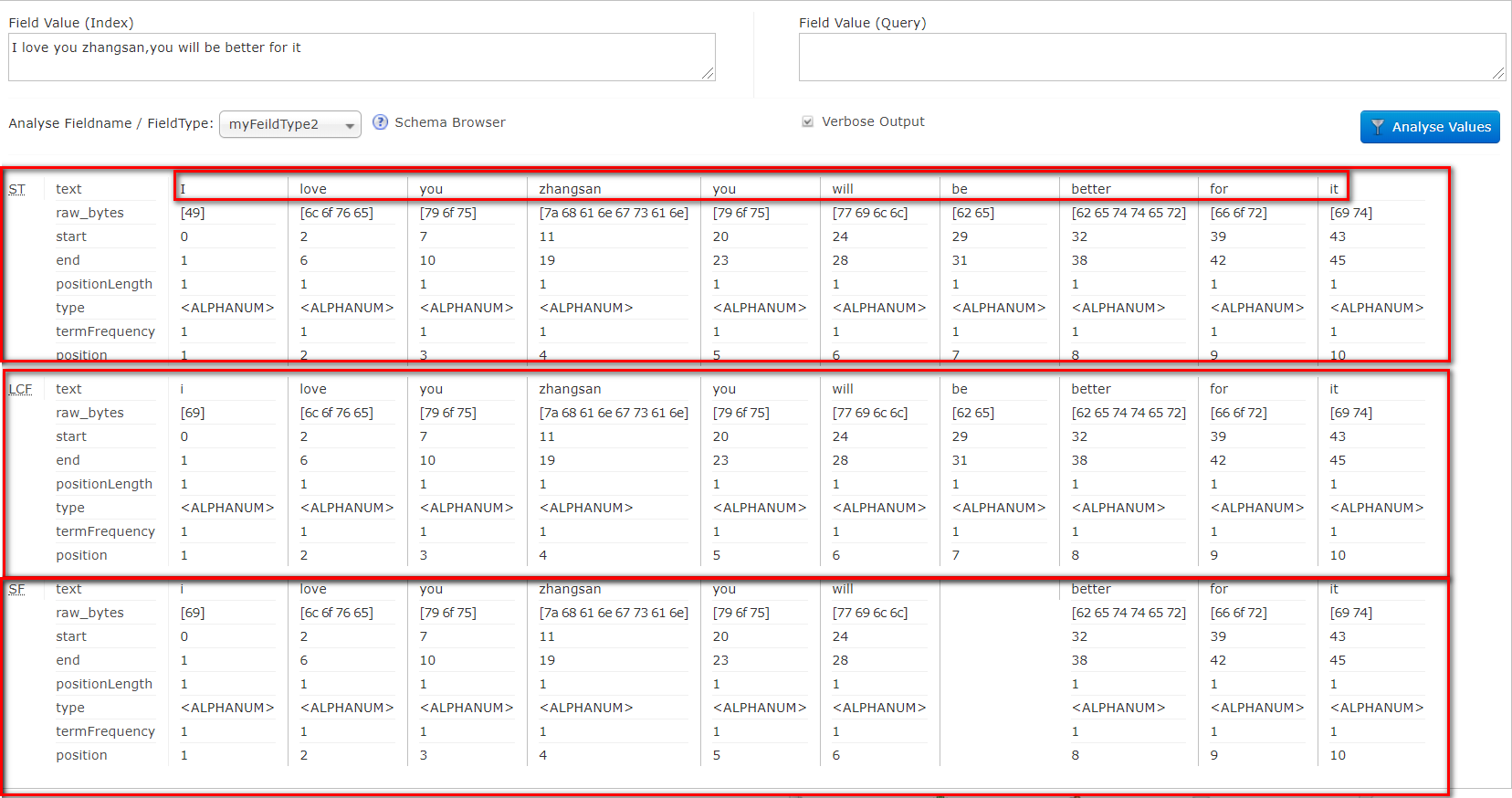
- 测试:
- 方式三:如果该类型字段索引、查询时需要使用不同的分析器,则需区分配置analyzerxml
<fieldType name="nametext" class="solr.TextField"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>- 测试索引分词效果:
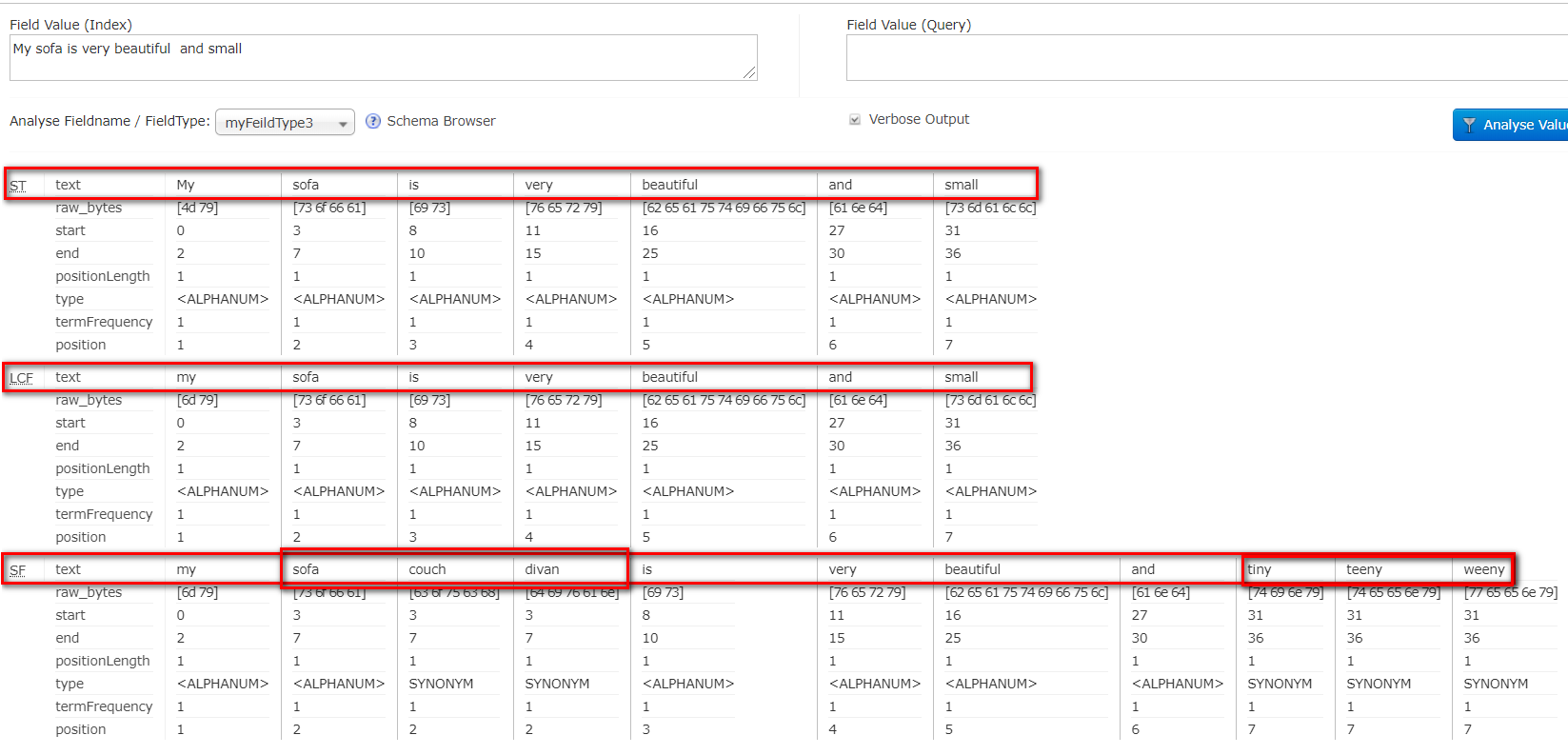
- 测试搜索分词效果
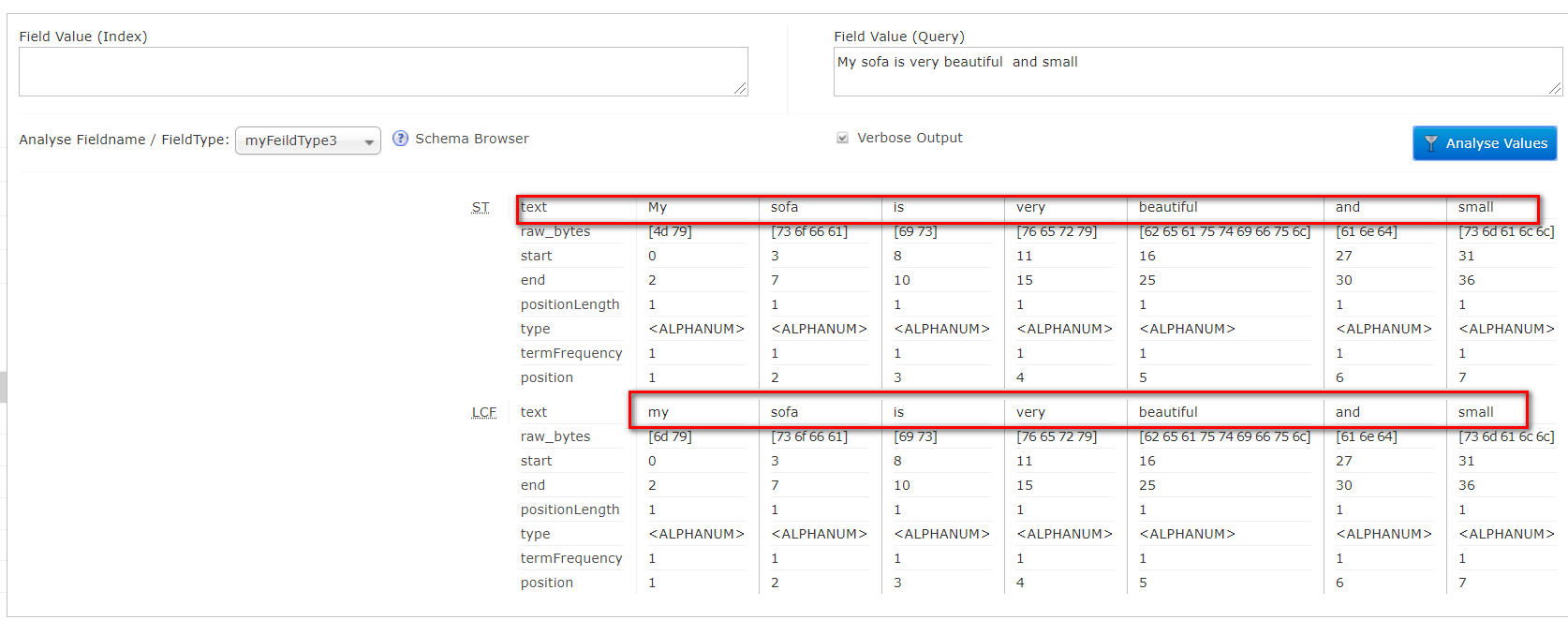
- 通过测试我们发现索引和搜索产生的分词结果是不同;
- 接下来我们使用myFeildType3定义一个域。使用该域创建一个文档。我们来测试;

- item_content:sofa可以搜索到吗?
- 索引的时候: sofa被分为couch,sofa,divan;
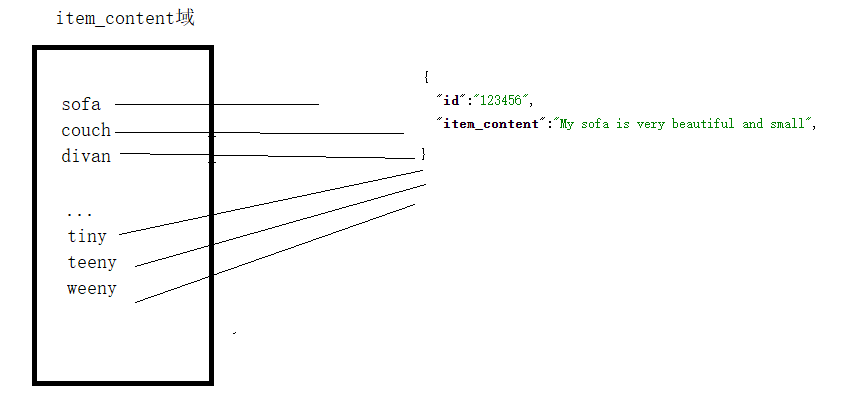
- 搜索的时候,sofa这个内容就被分为sofa这一个词;
- 索引的时候: sofa被分为couch,sofa,divan;
- item_content:couch可以搜索到吗?
- item_content:small可以搜索到吗?
- 索引的时候,small经过同义词过滤器变成 tiny,teeny,weeny 。small并没有和文档建立倒排索引关系;
- 搜索的时候small内容只能被分为samll这个词;所以找不到;
- item_content:sofa可以搜索到吗?
- 测试索引分词效果:
- 结论:
- 所以一般我们在定义FieldType的时候,索引和搜索往往使用的分析器规则相同;
- 或者索引的时候采用细粒度的分词器,目的是让更多的词和文档建立倒排索引;
- 搜索的时候使用粗粒度分词器,词分的少一点,提高查询的精度;
DateRangeField的使用

- Solr中提供的时间域类型( DatePointField, DateRangeField)是以时间毫秒数来存储时间的。要求域值以ISO-8601标准格式来表示时间:yyyy-MM-ddTHH:mm:ssZ。Z表示是UTC时间,如1999-05-20T17:33:18Z;
秒上可以带小数来表示毫秒如:1972-05-20T17:33:18.772Z、1972-05-20T17:33:18.77Z、1972-05-20T17:33:18.7Z - 域类型定义很简单:xml
<fieldType name="myDate" class="solr.DateRangeField" /> - 使用myDate域类型定义一个域xml
<field name="item_birthday" type="myDate" indexed="true" stored="true" /> - 基于item_birthday域来索引json
{"id":666777,"name":"xiaoming","item_birthday":"2020-3-6T19:21:22Z"} {"id":777888,"name":"misscang","item_birthday":"2020-3-6T19:22:22.333Z"} - 如何基于item_birthday搜索
- 语法:
查询时如果是直接的时间串,需要用转义字符进行转义: item_birthday:2020-2-14T19\:21\:22Z #用字符串表示的则不需要转义 item_birthday:"2020-2-14T19:21:22Z" - DateRangeField除了支持精确时间查询,也支持对间段数据的搜索,支持两种时间段表示方式:
方式一:截断日期,它表示整个日期跨度的精确指示。 方式二:时间范围,语法 [t1 TO t2] {t1 TO t2},中括号表示包含边界,大括号表示不包含边界 - 例子:
2000-11 #表示2000年11月整个月. 2000-11T13 #表示2000年11月每天的13点这一个小时 [2000-11-01 TO 2014-12-01] #日到日 [2014 TO 2014-12-01] #2014年开始到2014-12-01止. [* TO 2014-12-01] #2014-12-01(含)前. - 演示:
item_birthday:2020-11-21 item_birthday:[2020-02-14T19:21 TO 2020-02-14T19:22]
- 语法:
- Solr中还支持用 【NOW ±/ 时间】的数学表达式来灵活表示时间。
NOW+1MONTH #当前时间加上1个月 NOW+2MONTHS #当前时间加上两个月,复数要机上S NOW-1DAY NOW-2DAYS NOW/DAY, NOW/HOURS表示,截断。如果当前时间是2017-05-20T23:32:33Z,那么即是2017-05-20T00:00:00Z,2017-05-20T23:00:00Z。取当日的0点,去当前小时0点 NOW+6MONTHS+3DAYS/DAY 1972-05-20T17:33:18.772Z+6MONTHS+3DAYS/DAY- 演示:
item_birthday:[NOW-3MONTHS TO NOW] 生日在三个月内的; item_birthday:[NOW/DAY TO NOW] 当前时间的0点到当前时间 item_birthday:[NOW/HOURS TO NOW] 当前小时的0点到当前时间
EnumFieldType的使用

EnumFieldType 用于域值是一个枚举集合,且排序顺序可预定的情况,如新闻分类这样的字段。如果我们想定义一个域类型,他的域值只能取指定的值,我们就可以使用EnumFieldType 定义该域类型;
域类型定义:
xml<fieldType name="mySex" class="solr.EnumFieldType" enumsConfig="enumsConfig.xml" enumName="sexType" docValues="true" />属性:
参数 值 说明 enumsConfig enumsConfig.xml 指定枚举值的配置文件,绝对路径或相对内核conf/的相对路径 enumName 任意字符串 指定配置文件的枚举名。 docValues true/false 枚举类型必须设置 true enumsConfig.xml配置示例(若没有该文件则新建)如下:注意以UTF-8无BOM格式保存;
xml<?xml version="1.0" encoding="UTF-8"?> <enumsConfig> <enum name="sexType"> <value>男</value> <value>女</value> </enum> <enum name="new_cat"> <value>a</value> <value>b</value> <value>c</value> <value>d</value> </enum> </enumsConfig>演示:
xml<field name="item_sex" type="mySex" indexed="true" stored="true" />基于item_sex进行索引
json{"id":123321,"item_birthday":"1992-04-20T20:33:33Z","item_content":"i love sofa","item_sex":"男"} {"id":456564,"item_birthday":"1992-04-20T20:33:33Z","item_content":"i love sofa","item_sex":"女"}- 以下报错
json{"id":789987,"item_birthday":"1992-04-20T20:33:33Z","item_content":"i love sofa","item_sex":"妖"}
基于item_sex进行搜索
- item_sex:男
- item_sex:女
3.2.6 Solr的配置-DynamicField 动态域
- 在schema文件中我们还可以看到一种标签dynamicField,这个标签也是用来定义域的;他和field标签有什么区别呢
- 作用:如果某个业务中有近百个域需要定义,其中有很多域类型是相同,重复地定义域就十分的麻烦,因此可以定一个域名的规则,索引的时候,只要域名符合该规则即可;
- 如:整型域都是一样的定义,则可以定义一个动态域如下xml
<dynamicField name="*_i" type="pint" indexed="true" stored="true" /> - 注意:动态域只能用符号*通配符进行表示,且只有前缀和后缀两种方式
- 基于动态域索引;json
# bf_i就是符合上面动态域的域名; {"id":38383,"item_birthday":"1992-04-20T20:33:33Z","item_content":"i love sofa","item_sex":"女", "bf_i":5}
3.2.7 Solr的配置-复制域
- 在schema文件中我们还可以看到一种标签
<copyField />,这个标签是用来定义复制域的;复制域的作用是什么呢? - 作用:复制域允许将一个或多个域的数据填充到另外一个域中。他的最主要的作用,基于某一个域搜索,相当于在多个域中进行搜索;xml
<copyField source="cat" dest="text"/> <copyField source="name" dest="text"/> <copyField source="manu" dest="text"/> <copyField source="features" dest="text"/> <copyField source="includes" dest="text"/> <!-- cat name manu features includes text都是solr提前定义好的域。 将 cat name manu features includes域的内容填充到text域中; 将来基于text域进行搜索,相当于在cat name manu features includes域中搜索; --> - 演示:json
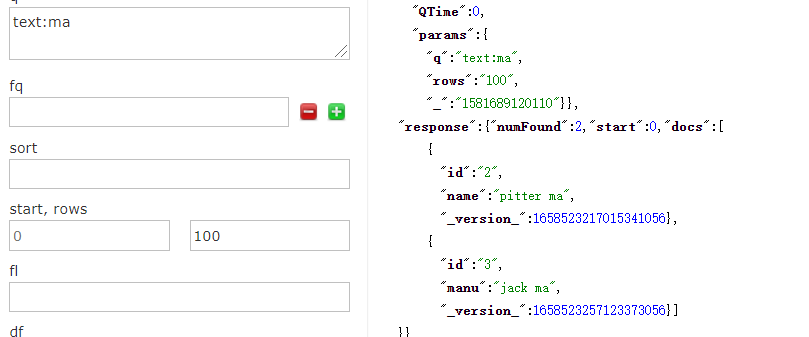
索引: {"id":1,"name":"pitter wang"} {"id":2,"name":"pitter ma"} {"id":3,"manu":"jack ma"} {"id":4,"manu":"joice liu"}- 搜索:
text:ma- 结果:
3.2.8 Solr的配置-主键域
- 指定用作唯一标识文档的域,必须。在solr中默认将id域作为主键域;也可以将其他改为主键域,但是一般都不会修改;
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<uniqueKey>id</uniqueKey>
<!-- 注意:主键域不可作为复制域,且不能分词。 -->3.2.9 Solr的配置-中文分词器
中文分词器的介绍
- 之前我们给大家讲解Solr中的分词器的时候,我们说Solr中最常用的分词器是Standard Tokenizer,
- Standard Tokenizer可以对英文完成精确的分词,但是对中文分词是有问题的。
- 之前我们在schema文件中定义的一个FieldType.name为myFeildType2,class为TextField。使用TextField定义的域类型需要指定分析器,该分析器中使用的分词器就是Standard Tokenizer。xml
<fieldType name="myFeildType2" class="solr.TextField"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory" /> <filter class="solr.LowerCaseFilterFactory" /> <filter class="solr.StopFilterFactory" words="stopwords.txt" /> </analyzer> </fieldType> - 测试myFeildType2的分词效果:
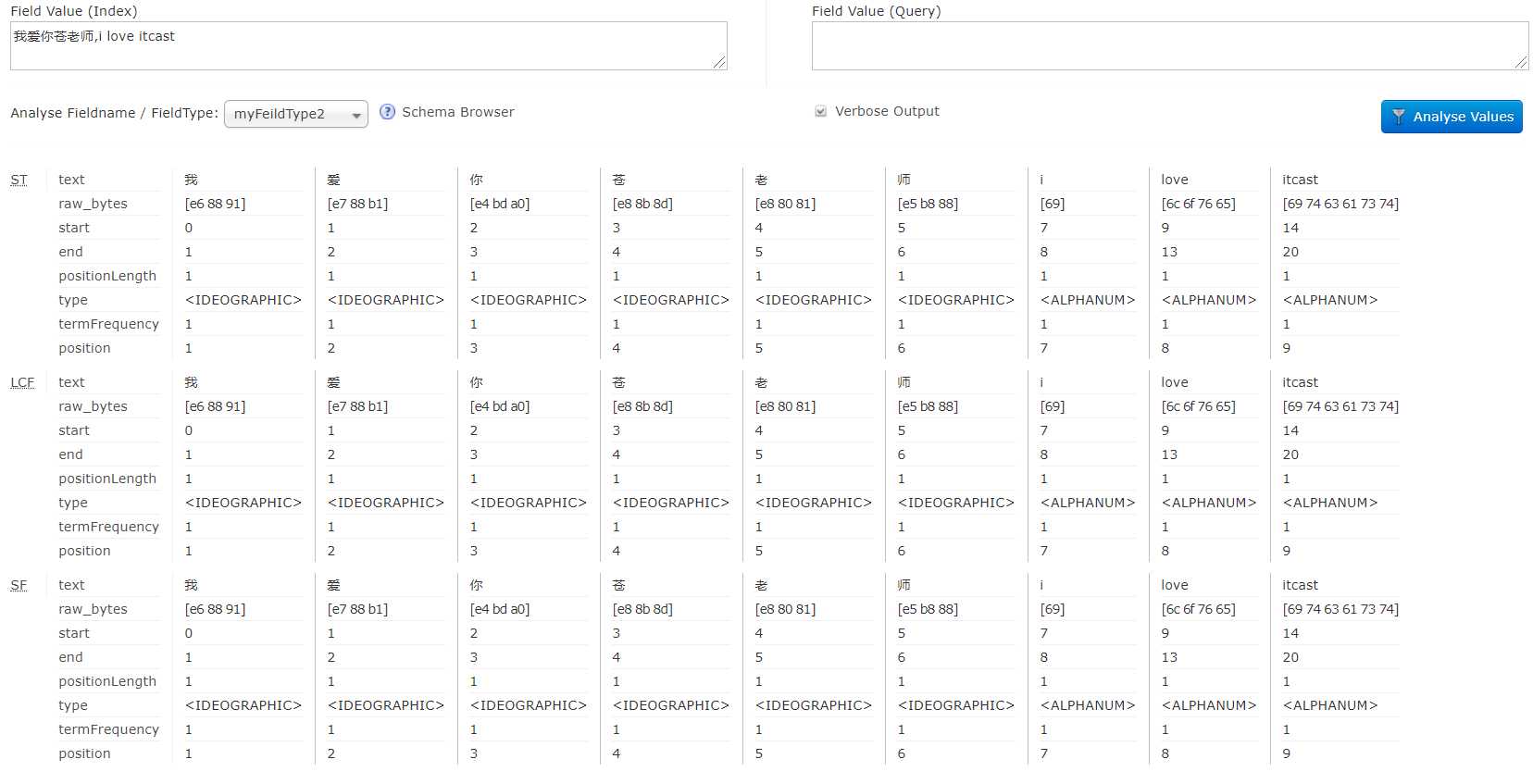
- 对于这种分词效果,显然不符合我们的要求.
- 中文分词一直以来是分词领域的一个难题,因为中文中的断词需要依赖语境。相同的一句话语境不同可能分出的词就不同。
- 在Solr中提供了一个中文分词器SmartCN。但是该分词器并没有纳入到Solr的正式包中,属于扩展包。
- 位置:solr-7.7.2\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.7.2.jar
- 而且SmartCN对中文分词也不太理想,目前市面上比较主流的中文分词器有IK,MMSeg4J,Ansj,Jcseg,TCTCLAS,HanLP.等
- 接下来我们就介绍一下这些分词器。并且使用这些分词器定义FieldType;
IK Analyzer
IK Analyzer是一个基于java语言开发的轻量级中文分词器包。采用词典分词的原理,允许使用者扩展词库。
使用流程:
- 1.下载地址:https://github.com/EugenePig/ik-analyzer-solr5
- 2.编译打包源码:mvn package
- 3.安装: 把ik-analyzer-solr5-5.x.jar拷贝到Tomcat的Solr/WEB-INF/lib目录;
- 4.配置: 把IKAnalyzer.cfg.xml和stopword.dic(停用词库),ext.dic(扩展词库)拷贝到Solr/WEB-INF/classes。
- 5.使用IK的分析器定义FiledType,IKAnalyzer分析器中提供了中分词器和过滤器。xml
<fieldType name ="text_ik" class ="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
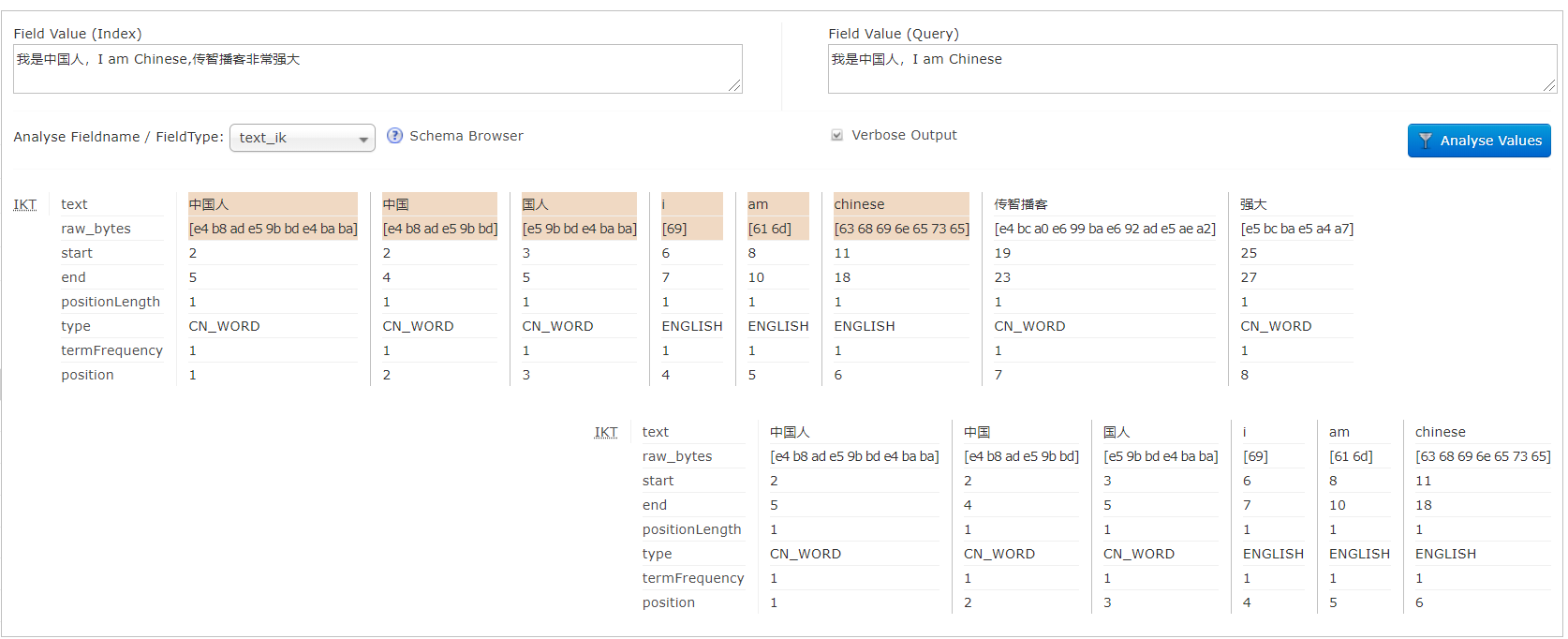
测试text_ik分词效果。

传智播客,被单字分词,此处我们也可以添加扩展词库,让传智播客分成一个词;
编辑Solr/WEB-INF/classes/ext.dic(扩展词库),加入传智播客;
再次测试
Ansj
- Ansj 是一个开源的 Java 中文分词工具,基于中科院的 ictclas 中文分词算法,比其他常用的开源分词工具(如mmseg4j)的分词准确率更高。Ansj中文分词是一款纯Java的、主要应用于自然语言处理的、高精度的中文分词工具,目标是“准确、高效、自由地进行中文分词”,可用于人名识别、地名识别、组织机构名识别、多级词性标注、关键词提取、指纹提取等领域,支持行业词典、用户自定义词典。
- 使用流程:
- 下载ansj以及其依赖包nlp-lang的源码
- 编译打包源码mvn package -DskipTests=true
- 打包ansj
- 打包nlp-lang
- 进入到ansj/plugin/ansj_lucene5_plugin目录,打包ansj_lucene5
- 安装:将以上三个jar包复制到solr/WEB-INF/lib目录
- 配置:将ansj的词库和配置文件复制到solr/WEB-INF/classes目录
- 使用ansj中提供的分析器,分词器配置FieldType
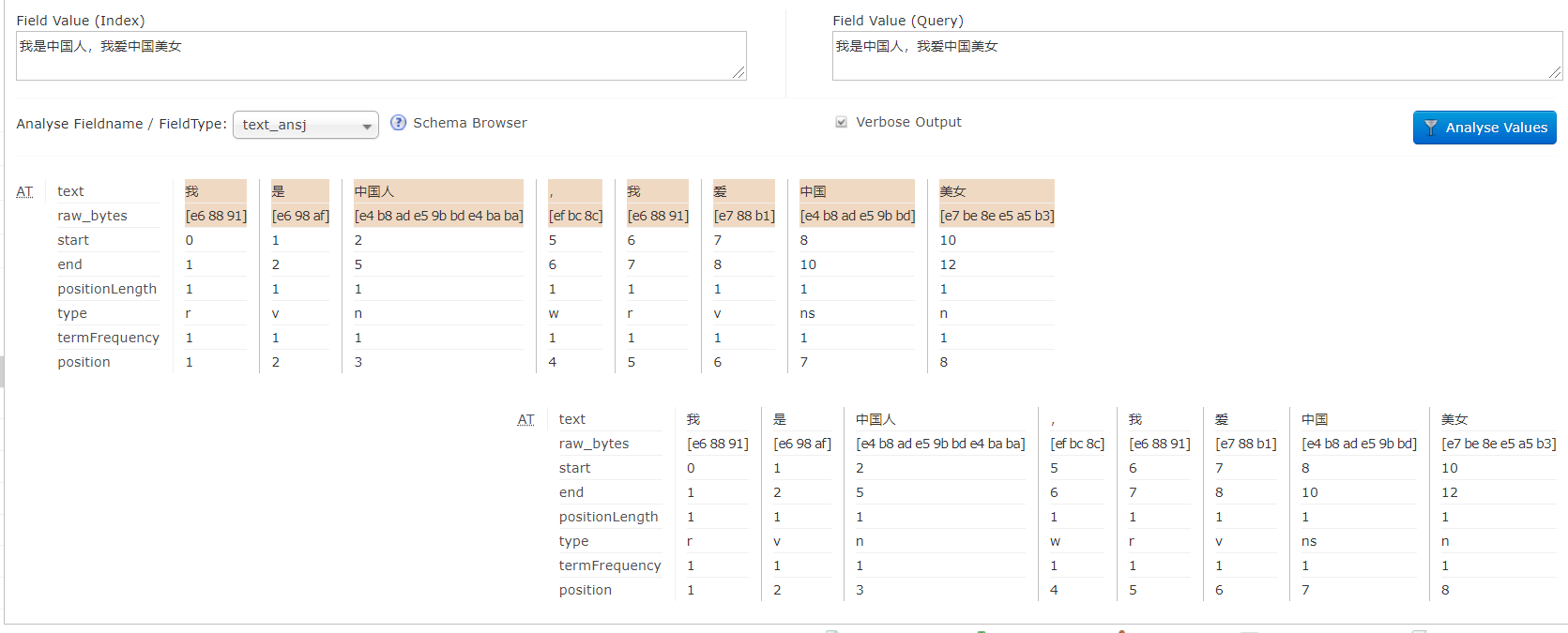
xml<fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" isQuery="false" /> </analyzer> <analyzer type="query"> <tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" /> </analyzer> </fieldType>- 测试
- 测试
MMSeg4J
- mmseg4j用Chih-Hao Tsai 的MMSeg算法实现的中文分词工具包,并实现lucene的analyzer和solr的r中使用。 MMSeg 算法有两种分词方法:Simple和Complex,都是基于正向最大匹配。Complex加了四个规则。官方说:词语的正确识别率达到了 98.41%。mmseg4j已经实现了这两种分词算法。
- 流程:
- 下载mmseg4j-core及mmseg4J-solr的源码;
- mmseg4j-core包含了一些词库;
- mmseg4J-solr包含了和solr整合相关的分析器
- https://github.com/chenlb/mmseg4j-core
- https://github.com/chenlb/mmseg4j-solr
- 编译打包源码:mvn package
- 安装: 把 mmseg4j-core.jar和mmseg4J-solr.jar复制到Solr/WEB-INF/lib
- 使用mmseg4j的分析器定义FiledType,mmseg4j提供了3种不同模式。分别针对不同情况的解析。
- tokenizer 的参数:
- dicPath 参数 - 设置词库位置,支持相对路径(相对于 solrCore).
- mode 参数 - 分词模式。
- complex:复杂模式,针对语义复杂的情况xml
<fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> </analyzer> </fieldtype> - max-word:最大词模式,针对分出的词最多xml
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/> </analyzer> </fieldtype> - simple:简单模式,针对一般情况xml
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="dic" /> </analyzer> </fieldtype>
- complex:复杂模式,针对语义复杂的情况
- 在collection1下创建词库目录dic
- 将 mmseg4j-core/resources/data目录中的词库文件复制到solr_home/collection1/dic目录
chars.dic 是单字的词,一般不用改动我们不需要关心它。 units.dic 是单字的单位,一般不用改动我们不需要关心它。 words.dic 是词库文件,一行一词,可以自己进行扩展词库。
- 测试mmseg4j分词效果。
txt近一百多年来,总有一些公司很幸运地、有意识或者无意识地站在技术革命的浪尖之上。一旦处在了那个位置,即使不做任何事,也可以随着波浪顺顺当当地向前漂个十年甚至更长的时间。在这十几年间,它们代表着科技的浪潮,直到下一波浪潮的来临。从一百年前算起,AT&T公司、IBM公司、苹果(Apple)公司 、英特尔(Intel) 公司、微软(Microsoft) 公司、和谷歌(Google)公司都先后被幸运地推到了浪尖。虽然,它们来自不同的领域,中间有些已经衰落或者正在衰落,但是它们都极度辉煌过。这些公司里的人,无论职位高低,在外人看来,都是时代的幸运儿。因为,虽然对一个公司来说,赶上一次浪潮不能保证其长盛不衰;但是,对一个人来说,一生赶上一次这样的浪潮就足够了。一个弄潮的年轻人,最幸运的,莫过于赶上一波大潮。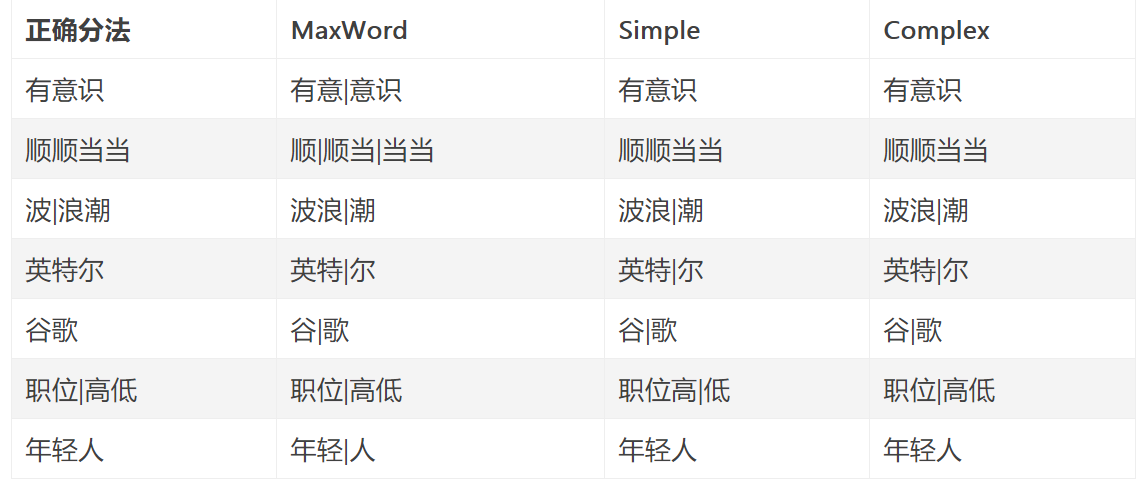
- 综上所述可以看出,三种分词方法存在着一些同样的错误,比如名词“英特尔“和”谷歌“都没有识别出来。综合比较Complex的分词方法准确率最高。
jcseg
- Jcseg是基于mmseg算法的一个轻量级Java中文分词工具包,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于Jetty的web服务器,方便各大语言直接http调用,同时提供了最新版本的lucene,solr和elasticsearch的搜索分词接口;
- 使用流程:
- 1.下载地址:https://gitee.com/lionsoul/jcseg
- 2.编译打包源码jcseg-core,jcseg-analyzer
- 3.安装: 将jcseg-analyze.jar和jcseg-core.jar复制到Solr/WEB-INF/lib目录
- 4.使用jcseg的分析器定义FieldType,Jcseg提供了很多模式;复杂模式最常用。
(1).简易模式:FMM算法,适合速度要求场合。 (2).复杂模式:MMSEG四种过滤算法,具有较高的歧义去除,分词准确率达到了98.41%。 (3).检测模式:只返回词库中已有的词条,很适合某些应用场合。 (4).最多模式:细粒度切分,专为检索而生,除了中文处理外(不具备中文的人名,数字识别等智能功能)其他与复杂模式一致(英文,组合词等)。 (5).分隔符模式:按照给定的字符切分词条,默认是空格,特定场合的应用。 (6).NLP模式:继承自复杂模式,更改了数字,单位等词条的组合方式,增加电子邮件,大陆手机号码,网址,人名,地名,货币等以及无限种自定义实体的识别与返回。 (7).n-gram模式:CJK和拉丁系字符的通用n-gram切分实现。xml<!-- 复杂模式分词: --> <fieldtype name="text_jcseg" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="complex"/> </analyzer> </fieldtype> <!-- 简易模式分词: --> <fieldtype name="textSimple" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="simple"/> </analyzer> </fieldtype> <!-- 检测模式分词: --> <fieldtype name="textDetect" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="detect"/> </analyzer> </fieldtype> <!-- 检索模式分词: --> <fieldtype name="textSearch" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="most"/> </analyzer> </fieldtype> <!-- NLP模式分词: --> <fieldtype name="textSearch" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="nlp"/> </analyzer> </fieldtype> <!-- 空格分隔符模式分词: --> <fieldtype name="textSearch" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="delimiter"/> </analyzer> </fieldtype> <!-- n-gram模式分词: --> <fieldtype name="textSearch" class="solr.TextField"> <analyzer> <tokenizer class="org.lionsoul.jcseg.analyzer.JcsegTokenizerFactory" mode="ngram"/> </analyzer> </fieldtype> - 扩展词库定义
- jcseg也支持对词库进行扩展
- 将jcseg的配置文件从jc-core/jcseg.properties复制到solr/WEB-INF/classess目录
- 编辑jcseg.properties配置文件,指定lexicon.path即词库位置。ini
lexicon.path = D:/jcseg/lexicon - 将jcseg\vendors\lexicon目录下的词库文件复制到 D:/jcseg/lexicon
- jcseg对这些词库文件进行分类
修改词库文件lex-place.lex加入新词 传智播客/ns/chuan zhi bo ke/null
- 测试jcseg分词效果。
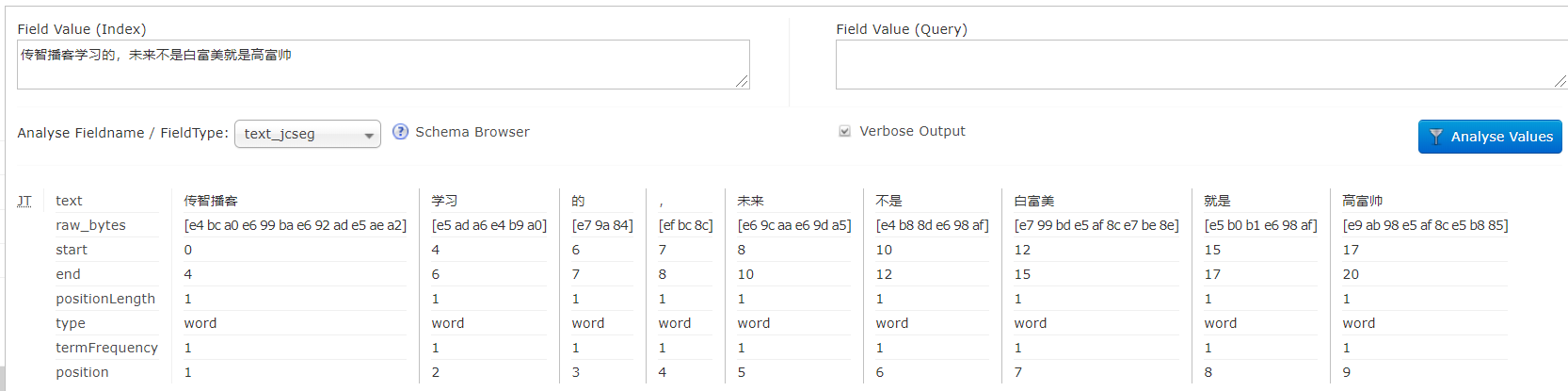
- 测试jcseg分词效果。
ICTCLAS(中科院分词器)
- ICTCLAS分词器是中国科学院计算技术研究所在多年研究工作积累的基础上,研制出了汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),基于完全C/C++编写,主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。先后精心打造五年,内核升级6次,目前已经升级到了ICTCLAS3.0。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器,商业收费。
- 使用流程:
- 下载ICTCLAS的分析器nlpir-analysis-cn-ictclas和ictclas SDK和jna.jar(java调用c的包):
- nlpir-analysis-cn-ictclas:https://github.com/NLPIR-team/nlpir-analysis-cn-ictclas
- ictclas SDK:https://github.com/NLPIR-team/NLPIR
- jna.jar:https://repo1.maven.org/maven2/net/java/dev/jna/jna/5.5.0/jna-5.5.0.jar
- 编译:打包nlpir-analysis-cn-ictclas源码生成lucene-analyzers-nlpir-ictclas-6.6.0.jar
- 安装:将lucene-analyzers-nlpir-ictclas-6.6.0.jar,jna.jar复制到solr/WEB-INF/lib目录
- 配置:在tomcat/bin目录下创建配置文件nlpir.properties,为什么要在tomcat/bin目录中创建配置文件呢?
- 我猜是他的代码中使用了相对路径。而不是读取classpath下面的文件;
inidata="D:/javasoft/NLPIR/NLPIR SDK/NLPIR-ICTCLAS" #Data directory‘s parent path,在ictclas SDK中; encoding=1 #0 GBK;1 UTF-8 sLicenseCode="" # License code,此处也可以看出其收费 userDict="" # user dictionary, a text file bOverwrite=false # whether overwrite the existed user dictionary or not- 配置fieldType,指定对应的分析器
xml<fieldType name="text_ictclas" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="org.nlpir.lucene.cn.ictclas.NLPIRTokenizerFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.nlpir.lucene.cn.ictclas.NLPIRTokenizerFactory"/> </analyzer> </fieldType>- 测试text_ictclas分词效果。
HanLP
- HanLP是由一系列模型与算法组成的java开源工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点;提供词法分析(中文分词、词性标注、命名实体识别)、句法分析、文本分类和情感分析等功能。
- 使用流程:
- 1.下载词典http://nlp.hankcs.com/download.php?file=data
- 2.下载hanlp的jar包和配置文件http://nlp.hankcs.com/download.php?file=jar 下载handlp整合lucene的jar包https://github.com/hankcs/hanlp-lucene-plugin
- 3.将词典文件压缩包data-for-1.7.zip解压到指定位置 eg:d:/javasoft下;
- 4.安装: 将hanlp.jar和hanlp-lucene-plugin.jar包复制到solr/WEB-INF/lib
- 5.配置:将配置文件hanlp.properties复制solr/WEB-INF/classes
- 6.配置:在hanlp.properties中指定词典数据的目录

- 7.配置停用词,扩展词等。
- 8.使用HanLP中提供的分析器配置FieldTypexml
<fieldType name="text_hanlp" class="solr.TextField"> <analyzer type="index"> <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/> </analyzer> <analyzer type="query"> <!-- 切记不要在query中开启index模式 --> <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/> </analyzer> </fieldType>
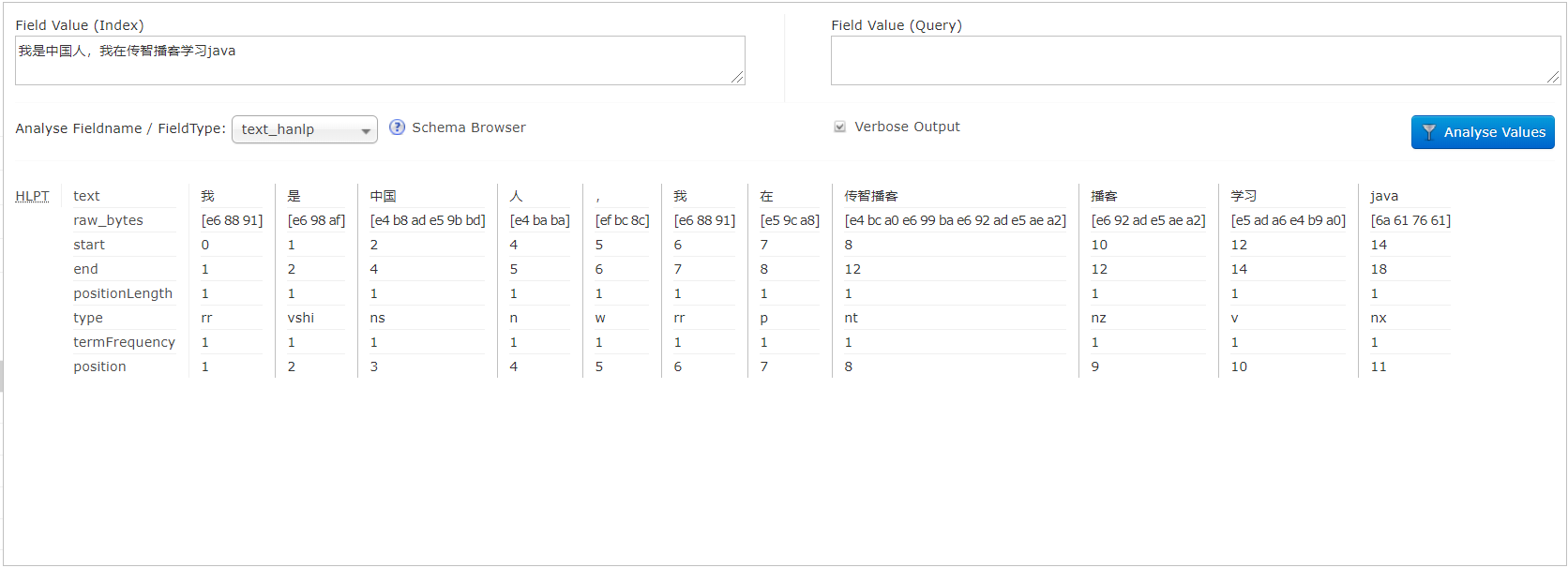
- 测试test_hanlp分词效果。
中文分词器建议
- 介绍了这么多的中文分词器,在实际开发中我们如何进行选择呢?
- 中文分词器核心就是算法和字典,算法决定了分词的效率,字典决定了分词的结果。词库不完善导致词语分不出来,虽然可以通过扩展词典进行补充,但是补充只能是发现问题再去补充,所以分词器自动发现新词的功能就很重要。
- CRF(条件随机场)算法是目前最好的识别新词的分词算法。Ansj和HanLp都支持CRF,自动补充词库;
- Ansj缺点是核心词典不能修改,只能借助扩展词典进行补充。
- HanLp是目前功能最齐全,社区最活跃的分词器。
- MMseg4J和Jcseg两者都采用MMseg算法。但是Jcseg更活跃。MMseg4J基本不再更新。
- IK分词器是使用最多的一种分词器,虽然词典不支持自动扩展词汇,但是简单,所以使用率最高;
- 最后一个就是Ictclas他是功能最强大的一款分词器,但是是基于C/C++编写,而且要进行商业授权。比较适合对分词要求较高且不差钱的公司。
- 综上:
- 一般对于追求简单来说建议使用IK分词器;
- 对分词要求较高,但是希望免费,可以使用HanLp;
- 关于中文分词器的使用我们就全部讲解完毕。
自定义分词器(了解)
我们都知道分析器由分词器和过滤器构成。
要想使用分析器,首先要定义分词器。如果不需要对分词结果进行过滤,过滤器是可选的。
之前我们在使用分词器的时候,都是使用Solr自带的分词器,比如标准分词器。当然也使用到第三方的一些中文分词器,比如IK分词器。为了更好的理解分析器的java体系结构,下面讲解自定义分词器。
定义分词器的步骤:
- 继承Tokenizer或者CharTokenizer抽象类;Tokenizer字符串级别的分词器,适合复杂分词器。CharTokenizer字符级别的分词器,适合简单分词器;
定义过滤器的步骤:
- 继承TokenFiler或者FilteringTokenFilter
需求:
- 自定义分词器将"This+is+my+family"按照+作为分隔符分成"This" "is" "My" "family";
- 搭建环境
- 创建模块,引入solr-core依赖,最好和当前solr版本一致xml
<dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-core</artifactId> <version>7.7.2</version> </dependency>
- 定义一个类继承CharTokenizer(字符级别的分词器)
javapublic class PlusSignTokenizer extends CharTokenizer { public PlusSignTokenizer() { } public PlusSignTokenizer(AttributeFactory factory) { super(factory); } //isTokenChar哪些字符是词; public boolean isTokenChar(int i) { //将什么字符作为分隔符进行分词 return i != '+'; } }- 定义分词器工厂管理分词器,定义类继承TokenizerFactory
javapublic class PlusSignTokenizerFactory extends TokenizerFactory { /** * 在schem配置文件中配置分词器的时候,指定参数args配置分词器时候的指定的参数 * <analyzer> * <tokenizer class="cn.itcast.tokenizer.PlausSignTokenizerFactory" mode="complex"/> * </analyzer> * @param args */ public PlusSignTokenizerFactory(Map<String, String> args) { //分词器属性配置 super(args); } @Override public Tokenizer create(AttributeFactory attributeFactory) { return new PlusSignTokenizer(attributeFactory); } }- package打包代码,将jar包复制到solr/WEB-INF/lib
- 配置FieldType
xml<fieldType name="text_custom" class="solr.TextField"> <analyzer> <tokenizer class="cn.itcast.tokenizer.PlausSignTokenizerFactory" /> </analyzer> </fieldType>- 测试
- 关于如何自定义一个分词器,我们就先说到这,在实际开发中我们基本上不会自己定义,主要体会流程;
自定义过滤器(了解)
- 上一节课,我们学习了分词器的定义,下面我们讲解定义过滤器。
- 在Solr中要定义一个过滤器,需要继承TokenFiler或者FilteringTokenFilter
- 需求:过滤掉"love"词
- 我们可以参考一个solr内置过滤器LenthFilter;java
public final class LengthFilter extends FilteringTokenFilter { private final int min; private final int max; //获取当前词 private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class); //构造方法接收三个参数,词的集合,词的最小长度和最大长度 public LengthFilter(TokenStream in, int min, int max) { super(in); if (min < 0) { throw new IllegalArgumentException("minimum length must be greater than or equal to zero"); } if (min > max) { throw new IllegalArgumentException("maximum length must not be greater than minimum length"); } this.min = min; this.max = max; } //该方法返回true,保留该词否则不保留; @Override public boolean accept() { final int len = termAtt.length(); return (len >= min && len <= max); } } - 定义一个类继承FilteringTokenFilter
- 定义成员变量,获取当前的词
javaprivate final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class);- 重写FilteringTokenFilter中accept() 方法决定保留哪些词。
javapublic class LoveTokenFilter extends FilteringTokenFilter { private String keyword; //获取当前词 private final CharTermAttribute termAtt = addAttribute(CharTermAttribute.class); public LoveTokenFilter(TokenStream in,String keyword) { super(in); this.keyword = keyword; } protected boolean accept() throws IOException { String token = termAtt.toString(); if(token.equalsIgnoreCase(keyword)) { return false; } return true; } }- 定义类继承TokenFilterFactory
javapublic class LoveTokenFilterFactory extends TokenFilterFactory { private String keywords; //调用父类无参构造 public LoveTokenFilterFactory(Map<String, String> args) throws IllegalAccessException { super(args); if(args== null) { throw new IllegalAccessException("必须传递keywords参数"); } this.keywords = this.get(args, "keywords"); } public TokenStream create(TokenStream input) { return new LoveTokenFilter(input,keywords); } }- 配置FieldType
xml<fieldType name="text_custom" class="solr.TextField"> <analyzer> <tokenizer class="cn.itcast.tokenizer.PlusSignTokenizerFactory" /> <filter class="cn.itcast.tokenfilter.LoveTokenFilterFactory" keywords="love" /> </analyzer> </fieldType>- 梳理工作流程:
- 打包安装重写测试
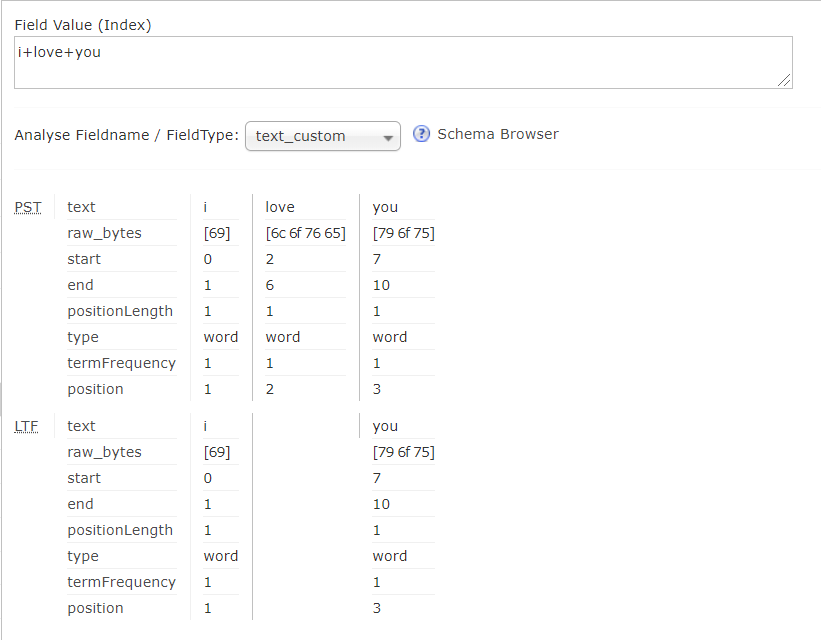
- 打包安装重写测试
自定义分析器(了解)
- 在Solr中我们通常会使用
<tokenizer>+<filter>的形式来组合分析器,这种方式耦合性低,使用起来灵活。 - 在Solr中也允许我们将一个分词器和一个过滤器直接封装到分析器类中;将来直接使用分析器。
- 流程:
- 定义类继承Analyzer类。
- 重写createComponents()方法;
- 将分词器和过滤器封装在createComponents()方法的返回值即可;
javapublic class MyAnalyzer extends Analyzer { @Override public TokenStreamComponents createComponents(String fieldName) { //自己的分词器 Tokenizer plusSignTokenizer = new PlusSignTokenizer(); //自带的过滤器 LowerCaseFilter lowerCaseFilter = new LowerCaseFilter(plusSignTokenizer); return new TokenStreamComponents(plusSignTokenizer, lowerCaseFilter); } }- 使用分析器声明FieldType
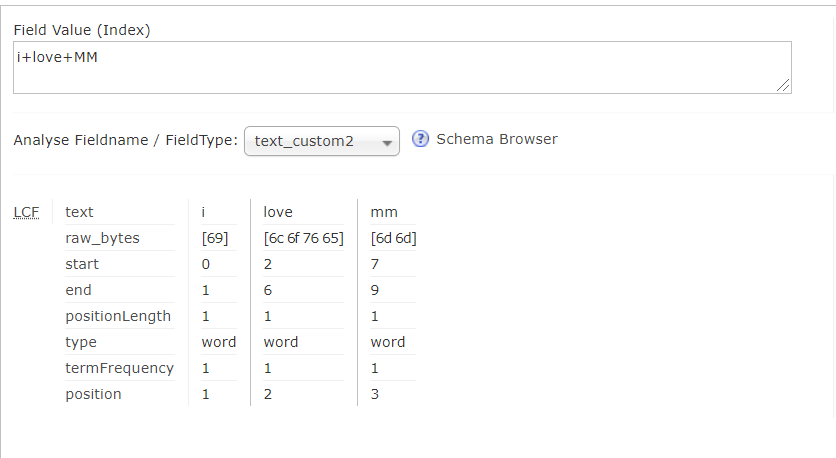
xml<fieldType name="text_custom2" class="solr.TextField"> <analyzer class="cn.itcast.analyzer.MyAnalyzer"></analyzer> </fieldType>- 打包测试
3.2.10 Solr的数据导入(DataImport)
- 在Solr后台管理系统中提供了一个功能叫DataImport,作用就是将数据库中的数据导入到索引库,简称DHI;
- DataImport如何将数据库中的数据导入到索引库呢?
- 查询数据库中的记录;
- 将数据库中的一条记录转化为Document,并进行索引;
- 需求:将以下表中数据导入到MySQL
sql脚本在资料中;
- 步骤:
- 准备:
- 创建MySQL数据库和表(略);
- 在schema文件中声明图书相关的业务域;xml
<!-- id:使用solr提供的id域; book_name:使用text_ik类型,因为该域中包含中文,索引,并且存储; book_price:使用pfloat类型,索引,并且存储; book_pic:使用string类型,不索引,存储; book_description:使用text_ik类型,索引,不存储; book_num:使用pint类型,索引,并且存储; --> <field name="book_name" type="text_ik" indexed="true" stored="true"/> <field name="book_price" type="pfloat" indexed="true" stored="true"/> <field name="book_pic" type="string" indexed="false" stored="true"/> <field name="book_description" type="text_ik" indexed="true" stored="false"/> <field name="book_num" type="pint" indexed="true" stored="true"/>
- 将MySQL的mysql驱动mysql-connector-5.1.16-bin.jar复制到solr\WEB-INF\lib中。
- 查看SolrCore中的配置文件solrconfig.xml,solrconfig.xml文件主要配置了solrcore自身相关的一些参数(后面我们再给大家讲解)。作用:指定DataImport将MySQL数据导入Solr的配置文件为solr-data-config.xml;
xml<requestHandler name="/dataimport" class="solr.DataImportHandler"> <lst name="defaults"> <str name="config">solr-data-config.xml</str> </lst> </requestHandler>- 编辑SolrCore/conf中solr-data-config.xml文件
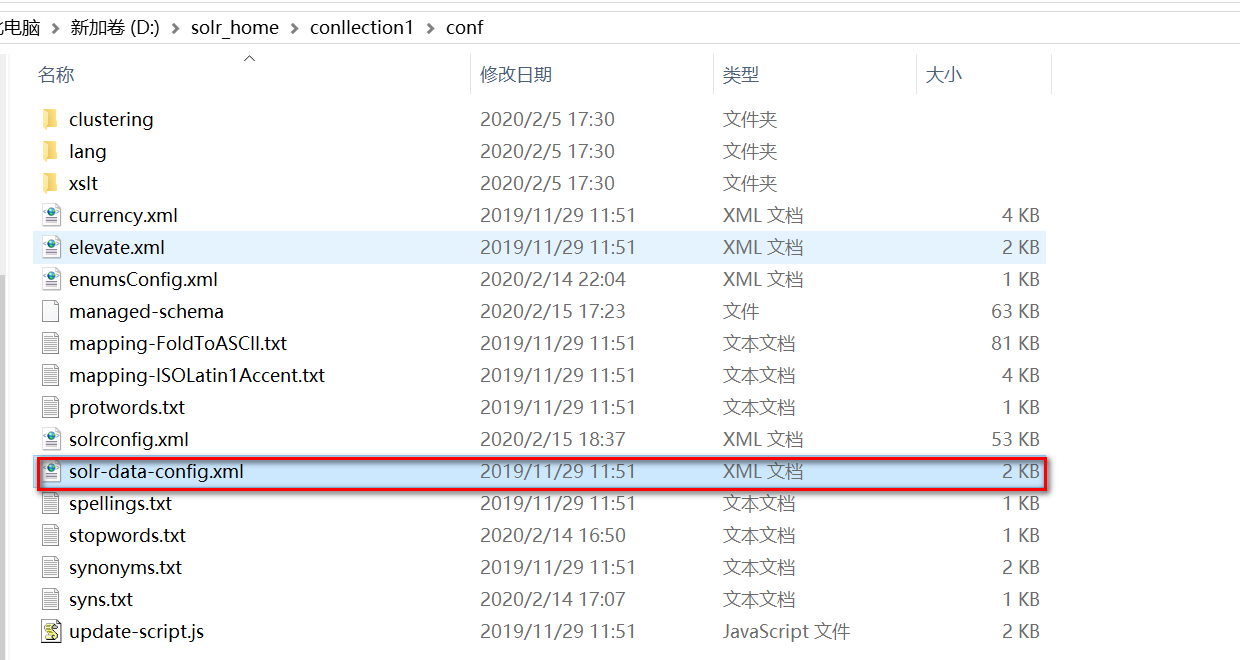
xml<dataConfig> <!-- 首先配置数据源指定数据库的连接信息 --> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/lucene" user="root" password="root" /> <document> <!-- entity作用:数据库中字段和域名如何映射 name:标识,任意 query:执行的查询语句 --> <entity name="book" query="select * from book"> <!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) --> <field column="id" name="id" /> <field column="name" name="book_name" /> <field column="price" name="book_price" /> <field column="pic" name="book_pic" /> <field column="description" name="book_description" /> <field column="num" name="book_num" /> </entity> </document> </dataConfig>- 编辑SolrCore/conf中solr-data-config.xml文件
- 使用DataImport导入。
- 使用DataImport导入。
3.2.11 solrconfig.xml
- 上一节在使用DataImport的时候,使用到了一个配置文件solrconfig.xml,这个配置文件是solr中常用的4个配置文件之一。但是相对schema文件,用的很少。
- solrconfig.xml作用:主要配置SolrCore相关的一些信息。Lucene的版本,第三方依赖包加载路径,索引和搜索相关的配置;JMX配置,缓存配置等;
- Lucene的版本配置;一般和Solr版本一致;
xml<luceneMatchVersion>7.7.2</luceneMatchVersion>- 第三方依赖包加载路径
xml<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" /> <!-- 告诉solr,第三方依赖包的位置。一般我们并不会在lib中进行设置,因为lib中的设置,只能该solrCore使用, 其他SolrCore无法使用,一般第三方的依赖包,我们直接会放在Solr/WEB-INF/lib下。所有的solrCore共享。 --> <!-- solr.install.dir:SolrCore所在目录,当前配置文件属于哪个SolrCore,solr.install.dir就是那个SolrCore目录 -->- 索引数据所在目录:默认位置SolrCore/data
xml<dataDir>${solr.data.dir:}</dataDir>- 用来配置创建索引的类
xml<directoryFactory name="DirectoryFactory" class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}" />- 用来设置Lucene倒排索引的编码工厂类,默认实现是官方提供的SchemaCodecFactory类。;
xml<codecFactory class="solr.SchemaCodecFactory"/>- 索引相关配置

- 索引相关配置
- 搜索相关配置
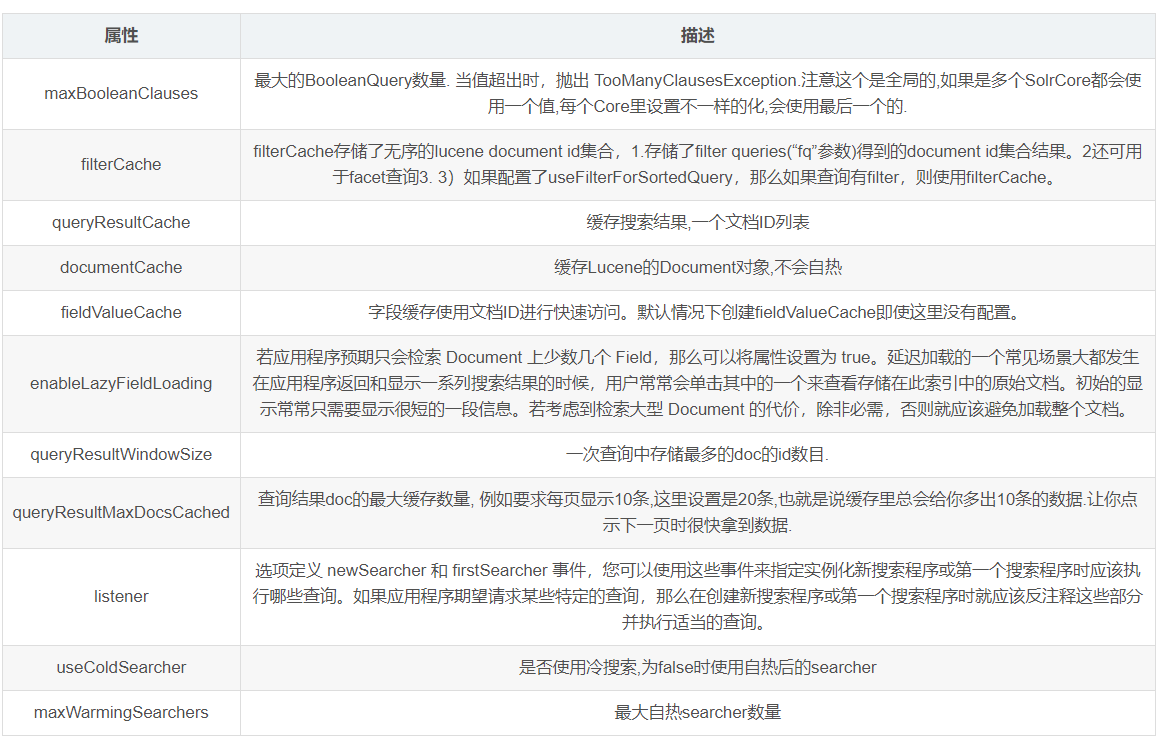
- 搜索相关配置
3.2.12 Query
- 接下来我们讲解后台管理系统中Query功能,Query的主要作用是查询;
- 接下来我们来讲解一下基本使用
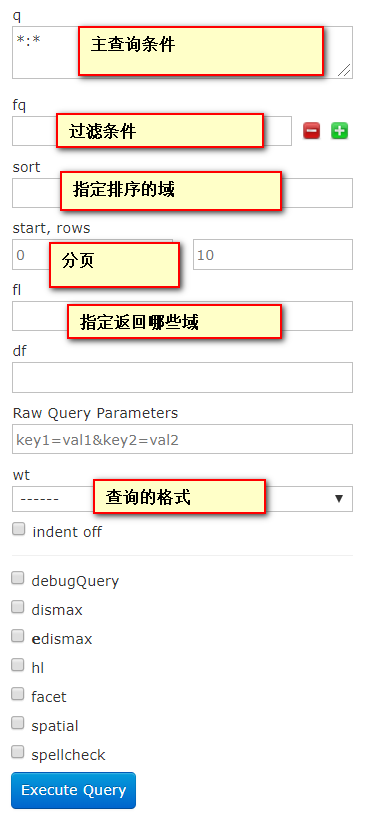
- q:表示主查询条件,必须有.
- fq:过滤条件。
- start,rows:指定分页;
- fl:指定查询结果文档中需要的域;
- wt:查询结果的格式,JSON/XML;
- 演示:
- 查询book_description中包含java;
- 查询book_description中包含java并且book_name中包含lucene;
- 对查询的结果按照价格升序,降序。
- 分页查询满足条件的第一页2条数据,第二页2条数据
- start=(页码-1) * 每页条数
- 将查询结果中id域去掉;
- 查询的结果以JSON形式返回;
3.2.13 SolrCore其它菜单
- overview(概览)
- 作用:包含基本统计如当前文档数,最大文档数;删除文档数,当前SolrCore配置目录;

- 作用:包含基本统计如当前文档数,最大文档数;删除文档数,当前SolrCore配置目录;
- files
- 作用:对SolrCore/conf目录下文件预览
- Ping:拼接Solr的连通性;
- Plugins:Solr使用的一些插件;
- Replication:集群状态查看,后面搭建完毕集群再来说;
- Schema:管理Schema文件中的Field,可以查看和添加域,动态域和复制域;

- 作用:对SolrCore/conf目录下文件预览
- SegmentsInfo
- 展示底层Lucence索引段,包括每个段的大小和数据条数。Solr底层是基于lucene实现的,索引数据最终是存储到SolrCore/data/index目录的索引文件中;这些索引文件有_e开始的, _0开始的....对应的就是不同的索引段。
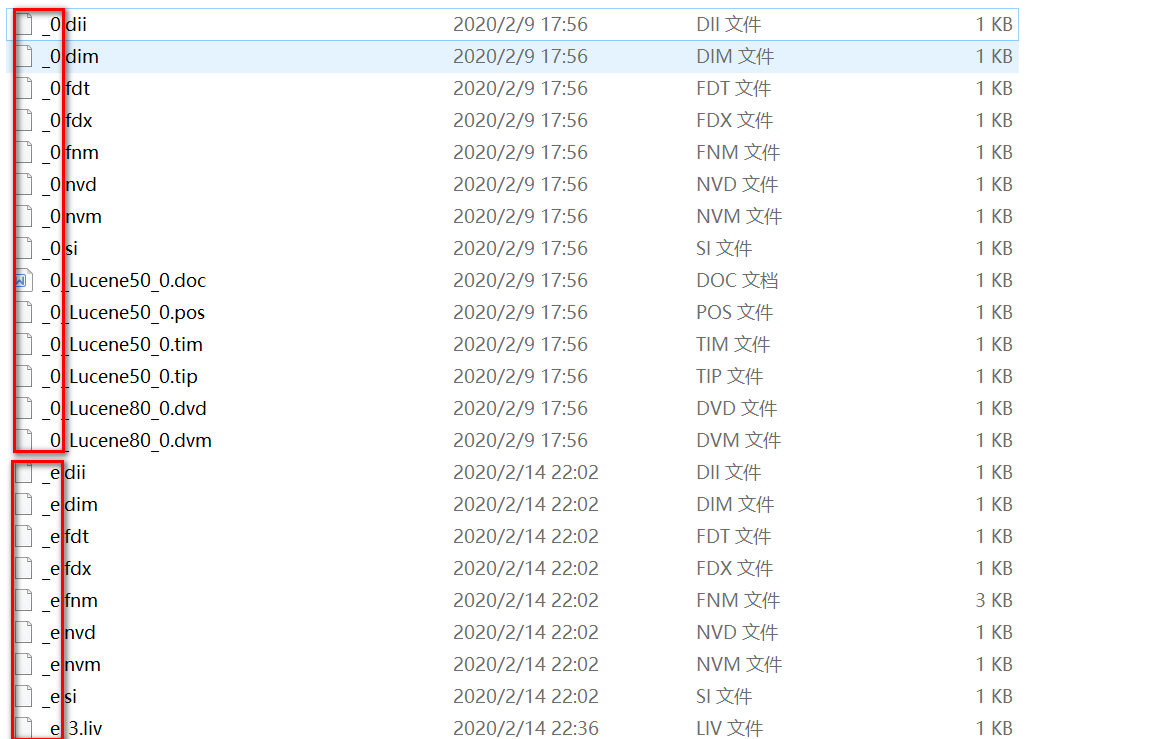
- 展示底层Lucence索引段,包括每个段的大小和数据条数。Solr底层是基于lucene实现的,索引数据最终是存储到SolrCore/data/index目录的索引文件中;这些索引文件有_e开始的, _0开始的....对应的就是不同的索引段。
4. Solr查询
4.1 Solr查询概述(理解)
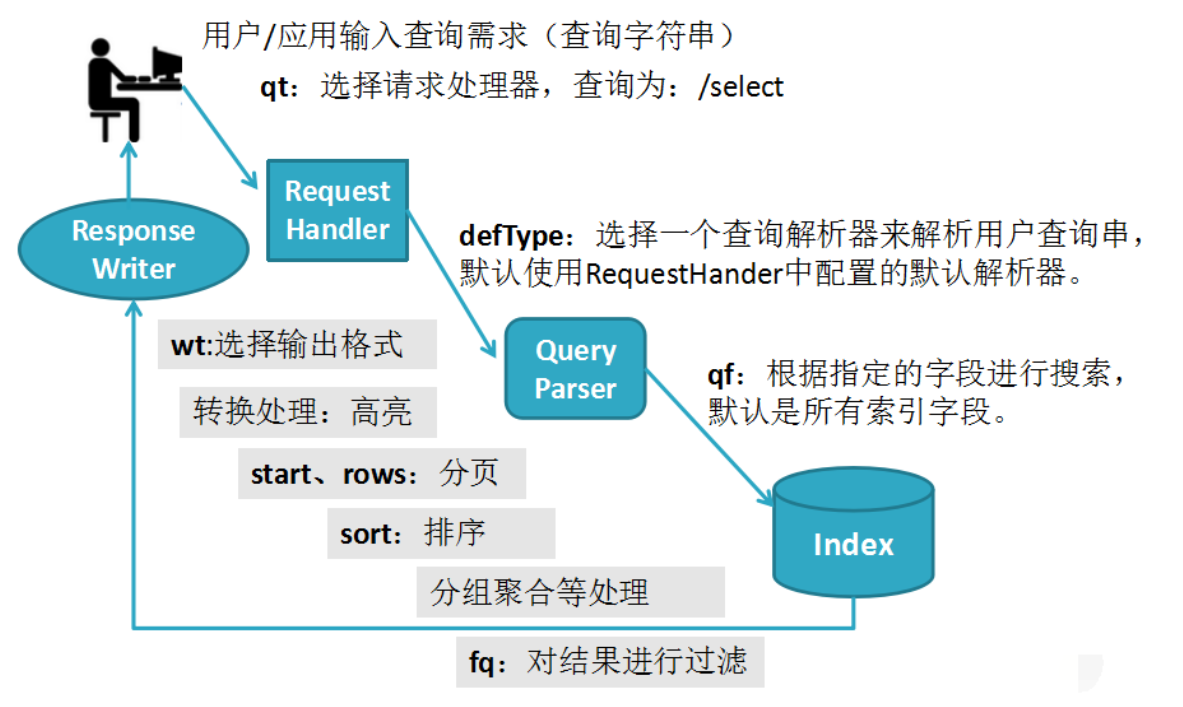
- 我们先从整体上对solr查询进行认识。当用户发起一个查询的请求,这个请求会被Solr中的Request Handler所接受并处理,Request Handler是Solr中定义好的组件,专门用来处理用户查询的请求。
- Request Handler相关的配置在solrconfig.xml中;
- 下面就是一个请求处理器的配置
- name:uri;
- class:请求处理器处理请求的类;
- lst:参数设置,eg:rows每页显示的条数。wt:结果的格式xml
<requestHandler name="/select" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="df">text</str> <!-- Change from JSON to XML format (the default prior to Solr 7.0) <str name="wt">xml</str> --> </lst> </requestHandler> <requestHandler name="/query" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <str name="wt">json</str> <str name="indent">true</str> <str name="df">text</str> </lst> </requestHandler>
- 这是Solr底层处理查询的组件,RequestHandler,简单认识一下;
- 宏观认识Solr查询的流程;
- 当用户输入查询的字符串eg:book_name:java,选择查询处理器/select.点击搜索;
- 请求首先会到达RequestHandler。RequestHandler会将查询的字符串交由QueryParser进行解析。
- QueryParser会从索引库中搜索出相关的结果。
- ResponseWriter将最终结果响应给用户;
- 通过这幅图大家需要明确的是,查询的本质就是基于Http协议和Solr服务进行请求和响应的一个过程。
4.2 相关度排序
- 上一节我们了解完毕Solr的查询流程,接下来我们来讲解相关度排序。什么叫相关度排序呢?
- 比如查询book_description中包含java的文档。
- 查询结果;

- 疑问:为什么id为40的文档再最前面?这里面就牵扯到Lucene的相关度排序;
- 相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。比如搜索“java”关键字,与该关键字最相关的文档应该排在前边。
- 影响相关度排序2个要素
- Term Frequency (tf):
- 指此Term在此文档中出现了多少次。tf越大说明越重要。词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“java”这个词,在文档中出现的次数很多,说明该文档主要就是讲java技术的。
- Document Frequency (df):
- 指有多少文档包含次Term。df越大说明越不重要。比如,在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,有越多的文档包含此词(Term),说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。
- Term Frequency (tf):
- 相关度评分
- Solr底层会根据一定的算法,对文档进行一个打分。打分比较高的排名靠前,打分比较低的排名靠后。
- 设置boost(权重)值影响相关度打分;
- 举例:查询book_name或者book_description域中包含java的文档;
- book_name中包含java或者book_description域中包含java的文档都会被查询出来。假如我们认为book_name中包含java应该排名靠前。可以给book_name域增加权重值。book_name域中有java的文档就可以靠前。
4.3 查询解析器(QueryParser)
- 之前我们在讲解查询流程的时候,我们说用户输入的查询内容,需要被查询解析器解析。所以查询解析器QueryParser作用就是对查询的内容进行解析。
- solr提供了多种查询解析器,为我们使用者提供了极大的灵活性及控制如何解析器查询内容。
- Solr提供的查询解析器包含以下:
- Standard Query Parser:标准查询解析器;
- DisMax Query Parser:DisMax 查询解析器;
- Extends DisMax Query Parser:扩展DisMax 查询解析器
- Others Query Parser:其他查询解析器
- 当然Solr也运行用户自定义查询解析器。需要继承QParserPlugin类;
- 默认解析器:lucene
- solr默认使用的解析器是lucene,即Standard Query Parser。Standard Query Parser支持lucene原生的查询语法,并且进行增强,使你可以方便地构造结构化查询语句。当然,它还有不好的,就是容错比较差,总是把错误抛出来,而不是像dismax一样消化掉。
- 查询解析器: disMax
- 只支持lucene查询语法的一个很小的子集:简单的短语查询、+ - 修饰符、AND OR 布尔操作;
- 可以灵活设置各个查询字段的相关性权重,可以灵活增加满足某特定查询文档的相关性权重。
- 查询解析器:edisMax
- 扩展 DisMax Query Parse 使支标准查询语法(是 Standard Query Parser 和 DisMax Query Parser 的复合)。也增加了不少参数来改进disMax。支持的语法很丰富;很好的容错能力;灵活的加权评分设置。
- 对于不同的解析器来说,支持的查询语法和查询参数,也是不同的。我们不可能把所有解析器的查询语法和参数讲完。实际开发也用不上。我们重点讲解的是Standard Query Parser支持的语法和参数。
4.4 查询语法
之前我们查询功能都是通过后台管理界面完成查询的。实际上,底层就是向Solr请求处理器发送了一个查询的请求,传递了查询的参数,下面我们要讲解的就是查询语法和参数。

地址信息 说明 http://localhost:8080/solr/collection1/select?q=book_name:java查询请求url http://localhost:8080/solrsolr服务地址 collection1 solrCore /select 请求处理器 ?q=xxx 查询的参数
4.4.1 基本查询参数
| 参数名 | 描述 |
|---|---|
| q | 查询条件,必填项 |
| fq | 过滤查询 |
| start | 结果集第一条记录的偏移量,用于分页,默认值0 |
| rows | 返回文档的记录数,用于分页,默认值10 |
| sort | 排序,格式: 默认是相关性降序 默认是相关性降序 |
| fl | 指定返回的域名,多个域名用逗号或者空格分隔,默认返回所有域 |
| wt | 指定响应的格式,例如xml、json等; |
- 演示:
查询所有文档:
`http://localhost:8080/solr/collection1/select?q=*:*`查询book_name域中包含java的文档
`http://localhost:8080/solr/collection1/select?q=book_name:java`查询book_description域中包含java,book_name中包含java。
http://localhost:8080/solr/collection1/select?q=book_description:java&fq=book_name:java查询第一页的2个文档
查询第一页的2个文档
http://localhost:8080/solr/collection1/select?q=*:*&start=0&rows=2 http://localhost:8080/solr/collection1/select?q=*:*&start=2&rows=2查询所有文档并且按照book_num升序,降序
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+asc http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+desc查询所有文档并且按照book_num降序,如果数量一样按照价格升序。
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_num+desc,book_price+asc查询所有数据文档,将id域排除
http://localhost:8080/solr/collection1/select?q=*:*&fl=book_name,book_price,book_num,book_pic对于基础查询来说还有其他的一些系统级别的参数,但是一般用的较少。简单说2个。
描述 参数名称 选择哪个查询解析器对q中的参数进行解析,默认lucene,还可以使用dismax|edismax defType 覆盖schema.xml的defaultOperator(有空格时用"AND"还是用"OR"操作逻辑).默认为OR。 q.op 默认查询字段 df(query type)指定那个类型来处理查询请求,一般不用指定,默认是standard qt查询结果是否进行缩进,开启,一般调试json,php,phps,ruby输出才有必要用这个参数 indent查询语法的版本,建议不使用它,由服务器指定默认值 version - defType:更改Solr的查询解析器的。一旦查询解析器发生改变,支持其他的查询参数和语法。
- q.op:如果我们搜索的关键字可以分出很多的词,到底是基于这些词进行与的关系还是或关系。
q=book_name:java编程 搜索book_name中包含java编程关键字 java编程---->java 编程词。 搜索的条件时候是book_name中不仅行包含java而且包含编程,还是只要有一个即可。 q=book_name&q.op=AND q=book_name&q.op=OR - df:指定默认搜索的域,一旦我们指定了默认搜索的域,在搜索的时候,我们可以省略域名,仅仅指定搜索的关键字 就可以在默认域中搜索
q=java&df=book_name
4.4.2 组合查询
上一节我们讲解了基础查询,接下来我们讲解组合查询。在Solr中提供了运算符,通过运算符我们就可以进行组合查询。
运算符 说明 ? 通配符,替代任意单个字符(不能在检索的项开始使用*或者?符号) * 通配符,替代任意多个字符(不能在检索的项开始使用*或者?符号) ~ 表示相似度查询,如查询类似于"roam"的词,我们可以这样写:roam~将找到形如foam和roams的单词;roam~0.8,检索返回相似度在0.8以上的文档。 邻近检索,如检索相隔10个单词的"apache"和"jakarta","jakarta apache"~10 AND 表示且,等同于 “&&” OR 表示或,等同于 “||” NOT 表示否 () 用于构成子查询 [] 范围查询,包含头尾 {} 范围查询,不包含头尾 + 存在运算符,表示文档中必须存在 “+” 号后的项 - 不存在运算符,表示文档中不包含 “-” 号后的项 实例:
?查询book_name中包含c?的词。http://localhost:8080/solr/collection1/select?q=book_name:c?*查询book_name总含spring*的词http://localhost:8080/solr/collection1/select?q=book_name:spring*~模糊查询book_name中包含和java及和java比较像的词,相似度0.75以上http://localhost:8080/solr/collection1/select?q=book_name:java~0.75 # java和jave相似度就是0.75.4个字符中3个相同。
AND查询book_name域中既包含servlet又包含jsp的文档;- 方式1:使用and
q=book_name:servlet AND book_name:jsp q=book_name:servlet && book_name:jsp - 方式2:使用+
q=+book_name:servlet +book_name:jsp
- 方式1:使用and
OR查询book_name域中既包含servlet或者包含jsp的文档;q=book_name:servlet OR book_name:jsp q=book_name:servlet || book_name:jspNOT查询book_name域中包含spring,并且id不是4的文档book_name:spring AND NOT id:4 +book_name:spring -id:4TO范围查询- 查询商品数量>=4并且<=10
http://localhost:8080/solr/collection1/select?q=book_num:[4 TO 10] - 查询商品数量>4并且<10
http://localhost:8080/solr/collection1/select?q=book_num:{4 TO 10} - 查询商品数量大于125
http://localhost:8080/solr/collection1/select?q=book_num:{125 TO *]
- 查询商品数量>=4并且<=10
4.4.3 q和fq的区别
- 在讲解基础查询的时候我们使用了q和fq,这2个参数从使用上比较的类似,很多使用者可能认为他们的功能相同,下面我们来阐述他们两者的区别;
- 从使用上:q必须传递参数,fq可选的参数。在执行查询的时候,必须有q,而fq可以有,也可以没有;
- 从功能上:
- q有2项功能
- 第一项:根据用户输入的查询条件,查询符合条件的文档。
- 第二项:使用相关性算法,匹配到的文档进行相关度排序。
- fq只有一项功能
- 对匹配到的文档进行过滤,不会影响相关度排序,效率高;
- q有2项功能
- 演示:
- 需求:查询book_descrption中包含java并且book_name中包含java文档;
- 单独使用q来完成;
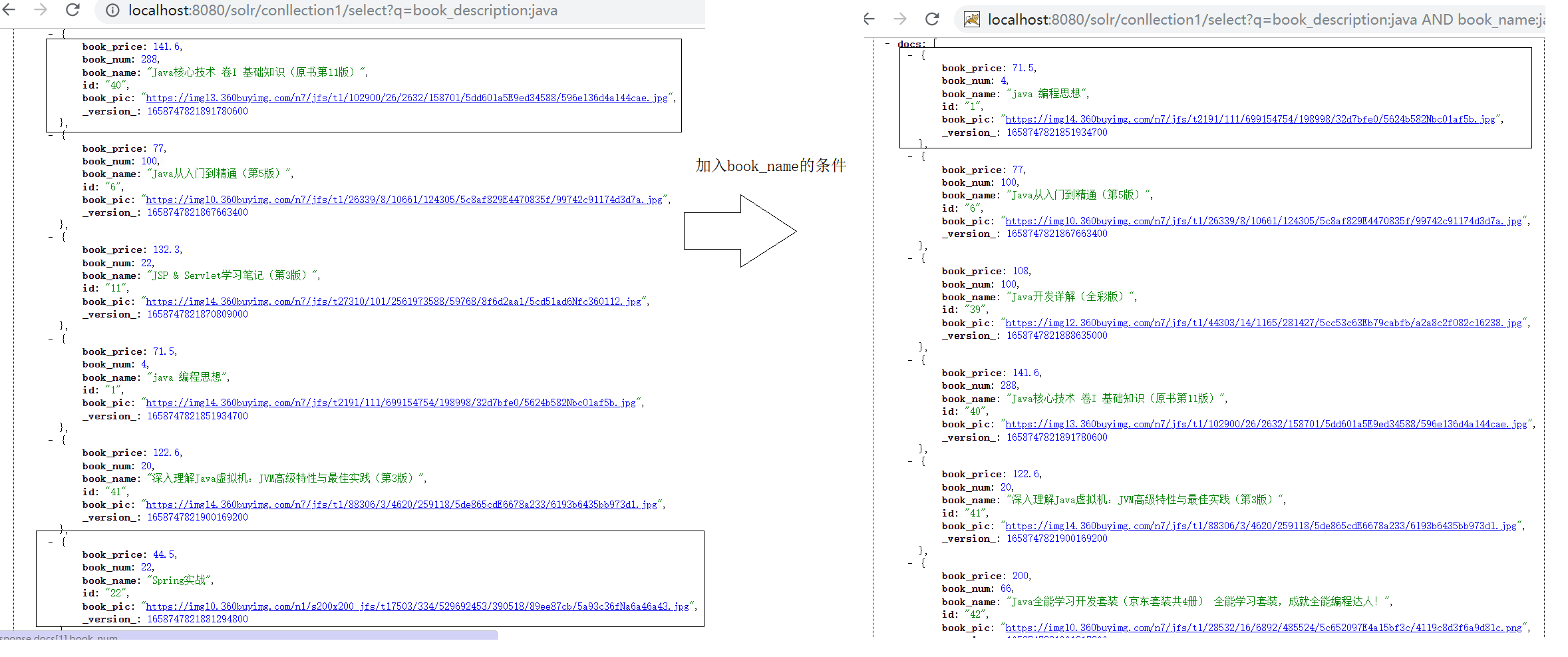
- 由于book_name条件的加入造成排序结果的改变;说明q查询符合条件的文档,也可以进行相关度排序;
- 使用q + fq完成
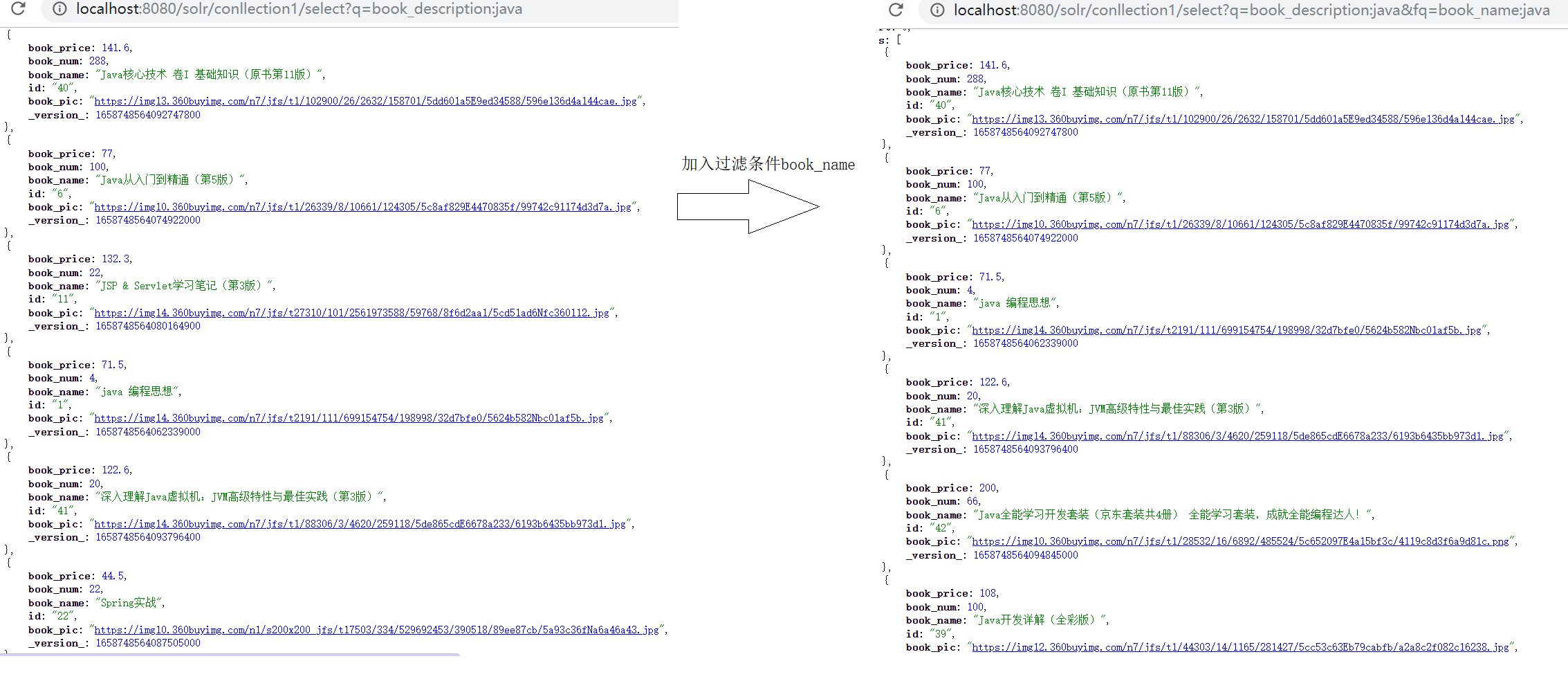
- 说明fq:仅仅只会进行条件过滤,不会影响相关度排序;
4.4.4 Solr返回结果和排序
返回结果的格式
在Solr中默认支持多种返回结果的格式。分别是XML,JSON,Ruby,Python,Binary Java,PHP,CVS等。下面是Solr支持的响应结果格式以及对应的实现类。
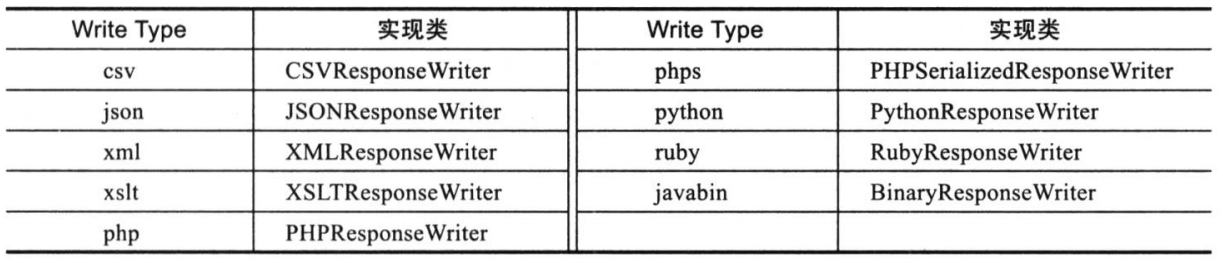
对于使用者来说,我们只需要指定wt参数即可;
查询所有数据文档返回xml
http://localhost:8080/solr/collection1/select?q=*:*&wt=xml返回结果文档包含的域
通过fl指定返回的文档包含哪些域。
返回伪域。
将返回结果中价格转化为分。product是Solr中的一个函数,表示乘法。后面我们会讲解。
http://localhost:8080/solr/collection1/select?q=*:*&fl=*,product(book_price,100)
域指定别名
- 上面的查询我们多了一个伪域。可以为伪域起别名fen
http://localhost:8080/solr/collection1/select?q=*:*&fl=*,fen:product(book_price,100)

- 同理也可以给原有域起别名
http://localhost:8080/solr/collection1/select?q=*:*&fl=name:book_name,price:book_price

- 上面的查询我们多了一个伪域。可以为伪域起别名fen
在Solr中我们是通过sort参数进行排序。
http://localhost:8080/solr/collection1/select?q=*:*&sort=book_price+asc&wt=json&rows=50特殊情况:某些文档book_price域值为null,null值排在最前面还是最后面。
定义域类型的时候需要指定2个属性sortMissingLast,sortMissingFirst
- sortMissingLast=true,无论升序还是降序,null值都排在最后
- sortMissingFirst=true,无论升序还是降序,null值都排在最前
xml<fieldtype name="fieldName" class="xx" sortMissingLast="true" sortMissingFirst="false"/>
4.5 高级查询-facet查询
4.5.1简单介绍
- facet 是 solr 的高级搜索功能之一 , 可以给用户提供更友好的搜索体验 。
- 作用:可以根据用户搜索条件 ,按照指定域进行分组并统计,类似于关系型数据库中的group by分组查询;
- eg:查询title中包含手机的商品,按照品牌进行分组,并且统计数量。sql
select brand,COUNT(*)from tb_item where title like '%手机%' group by brand - 适合场景:在电商网站的搜索页面中,我们根据不同的关键字搜索。对应的品牌列表会跟着变化。
- 这个功能就可以基于Facet来实现;


- Facet比较适合的域
- 一般代表了实体的某种公共属性的域 , 如商品的品牌,商品的分类 , 商品的制造厂家 , 书籍的出版商等等;
- Facet域的要求
- Facet 的域必须被索引, 一般来说该域无需分词,无需存储 ,无需分词是因为该域的值代表了一个整体概念 , 如商品的品牌 ” 联想 ” 代表了一个整体概念 , 如果拆成 ” 联 ”,” 想 ” 两个字都不具有实际意义 . 另外该字段的值无需进行大小写转换等处理 , 保持其原貌即可 .无需存储是因为查询到的文档中不需要该域的数据 , 而是作为对查询结果进行分组的一种手段 , 用户一般会沿着这个分组进一步深入搜索。
4.5.2 数据准备
- 为了更好的学习我们后面的知识,我们将商品表数据导入到Solr索引库;
- 删除图书相关的数据xml
<delete> <query>*:*</query> </delete> <commit /> - 创建和商品相关的域xml
<field name="item_title" type="text_ik" indexed="true" stored="true"/> 标题域 <field name="item_price" type="pfloat" indexed="true" stored="true"/> 价格域 <field name="item_images" type="string" indexed="false" stored="true"/> 图片域 <field name="item_createtime" type="pdate" indexed="true" stored="true"/> 创建时间域 <field name="item_updatetime" type="pdate" indexed="true" stored="true"/> 更新时间域 <field name="item_category" type="string" indexed="true" stored="true"/> 商品分类域 <field name="item_brand" type="string" indexed="true" stored="true"/> 品牌域 - 修改solrcore/conf目录中solr-data-config.xml配置文件,使用DataImport进行导入;xml
<entity name="item" query="select id,title,price,image,create_time,update_time,category,brand from tb_item"> <field column="id" name="id" /> <field column="title" name="item_title" /> <field column="price" name="item_price" /> <field column="image" name="item_images" /> <field column="create_time" name="item_createtime" /> <field column="update_time" name="item_updatetime" /> <field column="category" name="item_category" /> <field column="brand" name="item_brand" /> </entity> - 重启服务,使用DateImport导入;
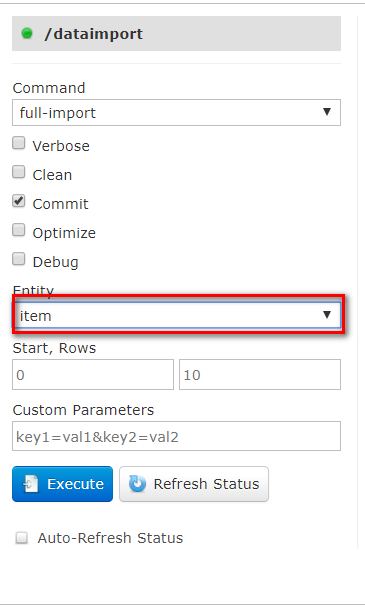
- 测试

4.5.3 Facet查询的分类
- facet_queries:表示根据条件进行分组统计查询。
- facet_fields:代表根据域分组统计查询。
- facet_ranges:可以根据时间区间和数字区间进行分组统计查询;
- facet_intervals:可以根据时间区间和数字区间进行分组统计查询;
4.5.4 facet_fields
- 需求:对item_title中包含手机的文档,按照品牌域进行分组,并且统计数量;
- 进行 Facet 查询需要在请求参数中加入 ”facet=on” 或者 ”facet=true” 只有这样 Facet 组件才起作用
- 分组的字段通过在请求中加入 ”facet.field” 参数加以声明
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand- 分组结果

- 如果需要对多个字段进行 Facet查询 , 那么将该参数声明多次;各个分组结果互不影响eg:还想对分类进行分组统计.
http://localhost:8080/solr/collection1/select?q=item_title:手机&facet=on&facet.field=item_brand&facet.field=item_category- 分组结果

- 其他参数的使用。
- 在facet中,还提供的其他的一些参数,可以对分组统计的结果进行优化处理;
参数 说明 facet.prefix 表示 Facet 域值的前缀 . 比如 ”facet.field=item_brand&facet.prefix=中国”, 那么对 item_brand字段进行 Facet 查询 , 只会分组统计以中国为前缀的品牌。 facet.sort 表示 Facet 字段值以哪种顺序返回 . 可接受的值为 true|false. true表示按照 count 值从大到小排列 . false表示按照域值的自然顺序( 字母 , 数字的顺序 ) 排列 . 默认情况下为 true. facet.limit 限制 Facet 域值返回的结果条数 . 默认值为 100. 如果此值为负数 , 表示不限制 . facet.offset 返回结果集的偏移量 , 默认为 0. 它与 facet.limit 配合使用可以达到分页的效果 facet.mincount 限制了 Facet 最小 count, 默认为 0. 合理设置该参数可以将用户的关注点集中在少数比较热门的领域 . facet.missing 默认为 ””, 如果设置为 true 或者 on, 那么将统计那些该 Facet 字段值为 null 的记录. facet.method 取值为 enum 或 fc, 默认为 fc. 该参数表示了两种 Facet 的算法 , 与执行效率相关 .enum 适用于域值种类较少的情况 , 比如域类型为布尔型 .fc适合于域值种类较多的情况。
- [facet.prefix] 分组统计以中国前缀的品牌
&facet=on &facet.field=item_brand &facet.prefix=中国
- [facet.sort] 按照品牌值进行字典排序
&facet=on &facet.field=item_brand &facet.sort=false
- [facet.limit] 限制分组统计的条数为10
&facet=on &facet.field=item_brand &facet.limit=10
- [facet.offset]结合facet.limit对分组结果进行分页
&facet=on &facet.field=item_brand &facet.offset=5 &facet.limit=5
- [facet.mincount] 搜索标题中有手机的商品,并且对品牌进行分组统计查询,排除统计数量为0的品牌
q=item_title:手机 &facet=on &facet.field=item_brand &facet.mincount=1
4.5.5 facet_ranges
- 除了字段分组查询外,还有日期区间,数字区间分组查询。作用:将某一个时间区间(数字区间),按照指定大小分割,统计数量;
- 需求:分组查询2015年,每一个月添加的商品数量;
- 参数:
参数 说明 facet.range 该参数表示需要进行分组的字段名 , 与 facet.field 一样 , 该参数可以被设置多次 , 表示对多个字段进行分组。 facet.range.start 起始时间/数字 , 时间的一般格式为 ” 1995-12-31T23:59:59Z”, 另外可以使用 ”NOW”,”YEAR”,”MONTH” 等等 , 具体格式可以参考 org.apache.solr.schema. DateField 的 java doc. facet.range.end 结束时间 数字 facet.range.gap 时间间隔 . 如果 start 为 2019-1-1,end 为 2020-1-1.gap 设置为 ”+1MONTH” 表示间隔1 个月 , 那么将会把这段时间划分为 12 个间隔段 . 注意 ”+” 因为是特殊字符所以应该用 ”%2B” 代替 . facet.range.hardend 取值可以为 true|false它表示 gap 迭代到 end 处采用何种处理 . 举例说明 start 为 2019-1-1,end 为 2019-12-25,gap 为 ”+1MONTH”,hardend 为 false 的话最后一个时间段为 2009-12-1 至 2010-1-1;hardend 为 true 的话最后一个时间段为 2009-12-1 至 2009-12-25 举例start为0,end为1200,gap为500,hardend为false,最后一个数字区间[1000,1200] ,hardend为true最后一个数字区间[1000,1500] facet.range.other 取值范围为 before|after|between|none|all, 默认为 none. before 会对 start 之前的值做统计 . after 会对 end 之后的值做统计 . between 会对 start 至 end 之间所有值做统计 . 如果 hardend 为 true 的话 , 那么该值就是各个时间段统计值的和 . none 表示该项禁用. all 表示 before,after,between都会统计. facet=on& facet.range=item_createtime& facet.range.start=2015-01-01T00:00:00Z& facet.range.end=2016-01-01T00:00:00Z& facet.range.gap=%2B1MONTH &facet.range.other=all - 结果
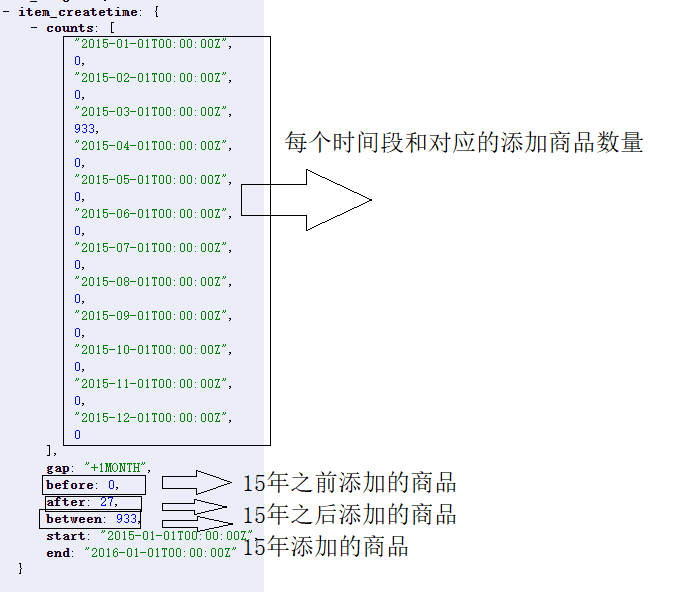
- 需求:分组统计价格在0~1000,1000~2000,2000~3000... 19000~20000及20000以上每个价格区间商品数量;
facet=on& facet.range=item_price& facet.range.start=0& facet.range.end=20000& facet.range.gap=1000& facet.range.hardend=true& facet.range.other=all - 结果:

4.5.6 facet_queries
- 在facet中还提供了第三种分组查询的方式facet query。提供了类似 filter query (fq)的语法可以更为灵活的对任意字段进行分组统计查询 .
- 需求:查询分类是平板电视的商品数量 品牌是华为的商品数量 品牌是三星的商品数量;
facet=on& facet.query=item_category:平板电视& facet.query=item_brand:华为& facet.query=item_brand:三星 - 测试结果

- 我们会发现统计的结果中对应名称tem_category:平板电视和item_brand:华为,我们也可以起别名;
facet=on& facet.query={!key=平板电视}item_category:平板电视& facet.query={!key=华为品牌}item_brand:华为& facet.query={!key=三星品牌}item_brand:三星 {---->%7B }---->%7D 这样可以让字段名统一起来,方便我们拿到请求数据后,封装成自己的对象; facet=on& facet.query=%7B!key=平板电视%7Ditem_category:平板电视& facet.query=%7B!key=华为品牌%7Ditem_brand:华为& facet.query=%7B!key=三星品牌%7Ditem_brand:三星

- 我们会发现统计的结果中对应名称tem_category:平板电视和item_brand:华为,我们也可以起别名;
4.5.7 facet_interval
- 在Facet中还提供了一种分组查询方式facet_interval。功能类似于facet_ranges。facet_interval通过设置一个区间及域名,可以统计可变区间对应的文档数量;
- 通过facet_ranges和facet_interval都可以实现范围查询功能,但是底层实现不同,性能也不同.
- 参数:
参数名 说明 facet.interval 此参数指定统计查询的域。它可以在同一请求中多次使用以指示多个字段。 facet.interval.set 指定区间。如果统计的域有多个,可以通过 f.<fieldname>.facet.interval.set语法指定不同域的区间。区间语法 区间必须以'(' 或 '[' 开头,然后是逗号(','),最终值,最后是 ')' 或']'。 例如:(1,10) - 将包含大于1且小于10的值[1,10])- 将包含大于或等于1且小于10的值 [1,10] - 将包含大于等于1且小于等于10的值 - 需求:统计item_price在[0-10]及[1000-2000]的商品数量和item_createtime在2019年~现在添加的商品数量
&facet=on &facet.interval=item_price &f.item_price.facet.interval.set=[0,10] &f.item_price.facet.interval.set=[1000,2000] &facet.interval=item_createtime &f.item_createtime.facet.interval.set=[2019-01-01T0:0:0Z,NOW] 由于有特殊符号需要进行URL编码[---->%5B ]---->%5D http://localhost:8080/solr/collection1/select?q=*:*&facet=on &facet.interval=item_price &f.item_price.facet.interval.set=%5B0,10%5D &f.item_price.facet.interval.set=%5B1000,2000%5D &facet.interval=item_createtime &f.item_createtime.facet.interval.set=%5B2019-01-01T0:0:0Z,NOW%5D - 结果

4.5.8 facet中其他的用法
- tag操作符和ex操作符
- 首先我们来看一下使用场景,当查询使用q或者fq指定查询条件的时候,查询条件的域刚好是facet的域;
- 分组的结果就会被限制,其他的分组数据就没有意义。
q=item_title:手机 &fq=item_brand:三星 &facet=on &facet.field=item_brand导致分组结果中只有三星品牌有数量,其他品牌都没有数量
- 如果想查看其他品牌手机的数量。给过滤条件定义标记,在分组统计的时候,忽略过滤条件;
- 查询文档是2个条件,分组统计只有一个条件
&q=item_title:手机 &fq={!tag=brandTag}item_brand:三星 &facet=on &facet.field={!ex=brandTag}item_brand {---->%7B }---->%7D &q=item_title:手机 &fq=%7B!tag=brandTag%7Ditem_brand:三星 &facet=on &facet.field=%7B!ex=brandTag%7Ditem_brand - 测试结果:

4.5.9 facet.pivot
- 多维度分组查询。听起来比较抽象。
- 举例:统计每一个品牌和其不同分类商品对应的数量;
品牌 分类 数量 华为 手机 200 华为 电脑 300 三星 手机 200 三星 电脑 20 三星 平板电视 200 。。。 。。。 - 这种需求就可以使用维度查询完成。
&facet=on &facet.pivot=item_brand,item_category - 测试结果

4.6 高级查询-group查询
4.6.1 group介绍和入门
- solr group作用:将具有相同字段值的文档分组,并返回每个组的顶部文档。 Group和Facet的概念很像,都是用来分组,但是分组的结果是不同;
- group查询相关参数
参数 类型 说明 group 布尔值 设为true,表示结果需要分组 group.field 字符串 需要分组的字段,字段类型需要是StrField或TextField group.func 查询语句 可以指定查询函数 group.query 查询语句 可以指定查询语句 rows 整数 返回多少组结果,默认10 start 整数 指定结果开始位置/偏移量 group.limit 整数 每组返回多数条结果,默认1 group.offset 整数 指定每组结果开始位置/偏移量 sort 排序算法 控制各个组的返回顺序 group.sort 排序算法 控制每一分组内部的顺序 group.format grouped/simple 设置为simple可以使得结果以单一列表形式返回 group.main 布尔值 设为true时,结果将主要由第一个字段的分组命令决定 group.ngroups 布尔值 设为true时,Solr将返回分组数量,默认fasle group.truncate 布尔值 设为true时,facet数量将基于group分组中匹相关性高的文档,默认fasle group.cache.percent 整数0-100 设为大于0时,表示缓存结果,默认为0。该项对于布尔查询,通配符查询,模糊查询有改善,却会减慢普通词查询。 - 需求:查询Item_title中包含手机的文档,按照品牌对文档进行分组;
q=item_title:手机 &group=true &group.field=item_brand group分组结果和Fact分组查询的结果完全不同,他把同组的文档放在一起,显示该组文档数量,仅仅展示了第一个文档。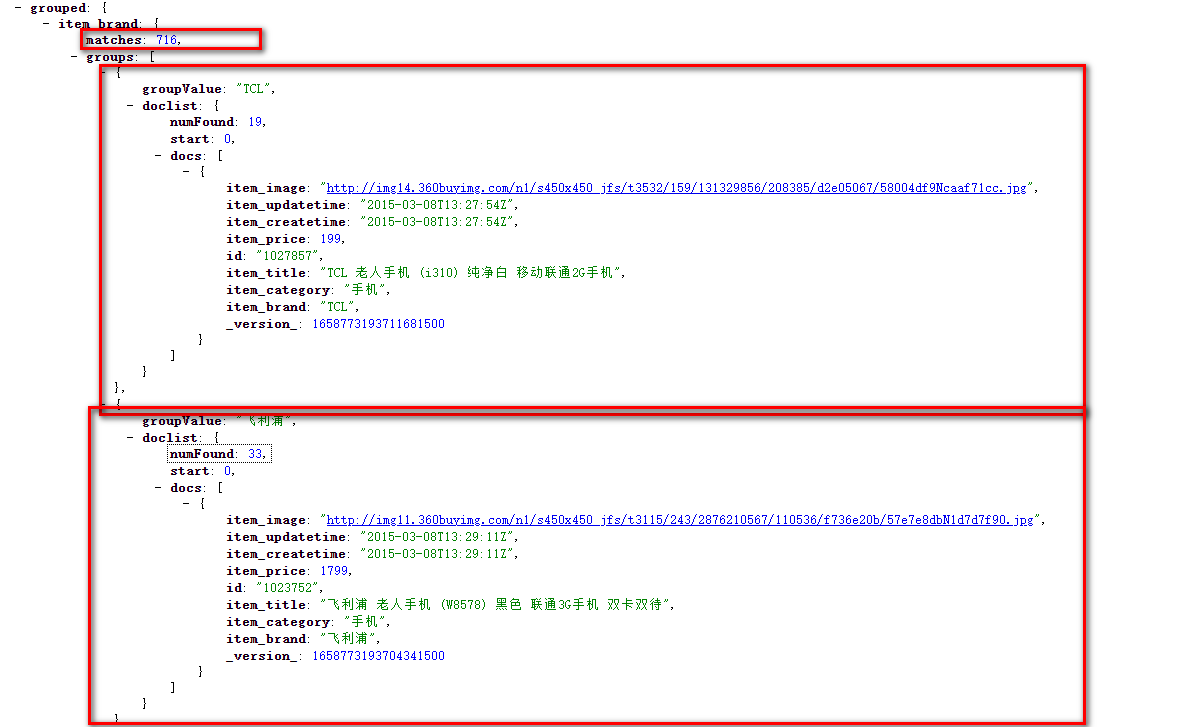
4.6.2 group参数-分页参数
- 上一节我们讲解了group的入门,接下来我们对group中的参数进行详解。
- 首先我们先来观察一下入门的分组结果。只返回10个组结果。

- [rows]通过rows参数设置返回组的个数。
q=item_title:手机&group=true&group.field=item_brand&rows=13 比上面分组结果多了三个组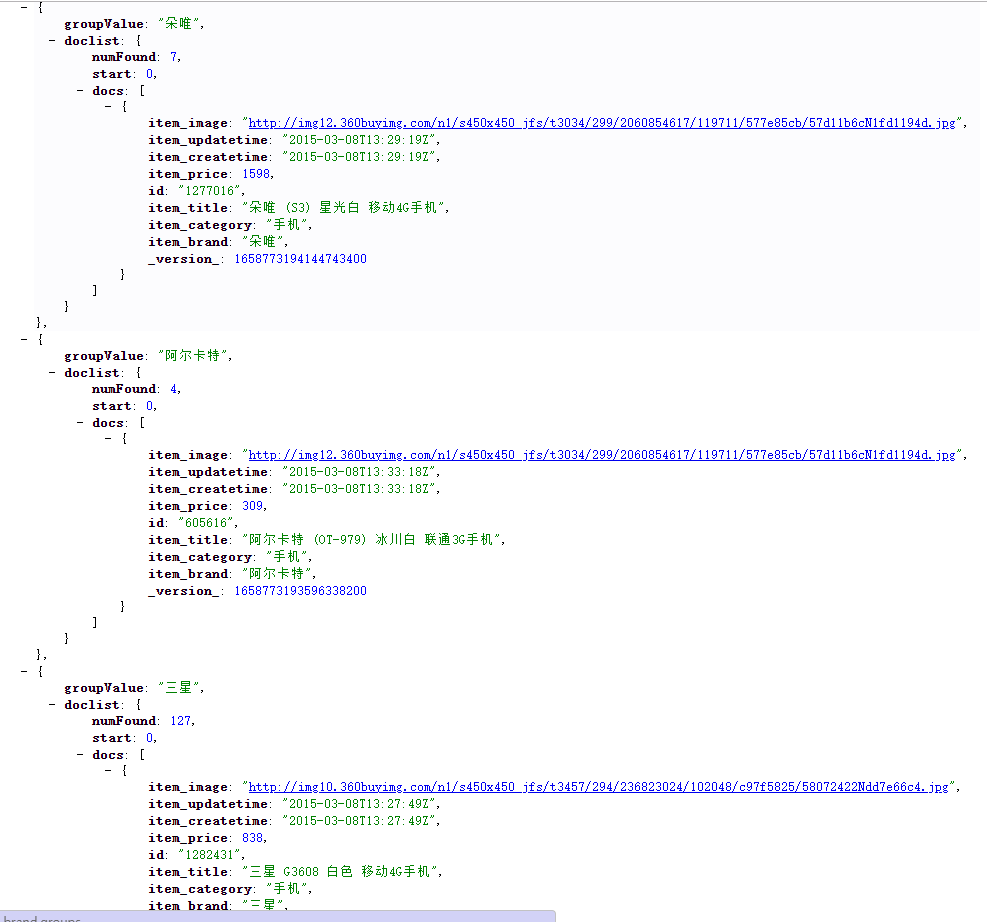
- 通过start和rows参数结合使用可以对分组结果分页;查询第一页3个分组结果
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3
- 除了可以对分组结果进行分页,可以对组内文档进行分页。默认情况下。只展示该组顶部文档。
- 需求:展示每组前5个文档。
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=3 &group.limit=5&group.offset=0
4.6.3 group参数-排序参数
- 排序参数分为分组排序和组内文档排序;
- [sort]分组进行排序
- 需求:按照品牌名称进行字典排序
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=5 &group.limit=5&group.offset=0 &sort=item_brand asc - [group.sort]组内文档进行排序
- 需求:组内文档按照价格降序;
q=item_title:手机&group=true&group.field=item_brand&start=0&rows=5 &group.limit=5&group.offset=0 &group.sort=item_price+desc
4.6.4 group查询结果分组
- 在group中除了支持根据Field进行分组,还支持查询条件分组。
- 需求:对item_brand是华为,三星,TCL的三个品牌,分组展示对应的文档信息。
q=item_title:手机 &group=true &group.query=item_brand:华为 &group.query=item_brand:三星 &group.query=item_brand:TCL
4.6.5 group 函数分组(了解)
- 在group查询中除了支持Field分组,Query分组。还支持函数分组。
- 按照价格范围对商品进行分组。0~1000属于第1组,1000~2000属于第二组,否则属于第3组。
q=*:*& group=true& group.func=map(item_price,0,1000,1,map(item_price,1000,2000,2,3))map(x,10,100,1,2) 在函数参数中的x如果落在[10,100)之间,则将x的值映射为1,否则将其值映射为2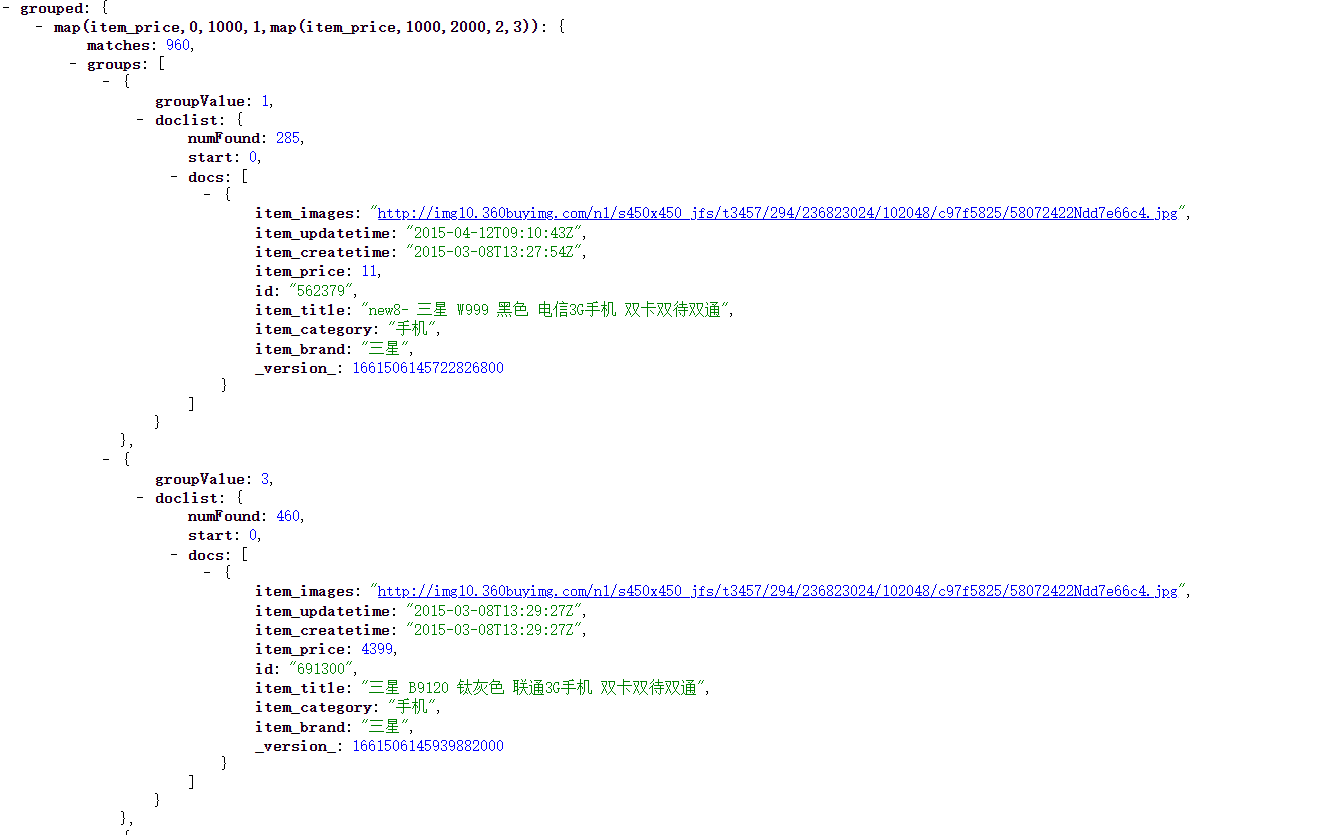
4.6.7 group其他参数
- group.ngroups:是否统计组数量
q=item_title:手机 &group=true &group.field=item_brand &group.ngroups=true - group.cache.percent
- Solr Group查询相比Solr的标准查询来说,速度相对要慢很多。
- 可以通过group.cache.percent参数来开启group查询缓存。该参数默认值为0.可以设置为0-100之间的数字
- 该值设置的越大,越占用系统内存。对于布尔类型等分组查询。效果比较明显。
- group.main
- 获取每一个分组中相关度最高的文档即顶层文档,构成一个文档列表。
q=item_title:手机 &group.field=item_brand &group=true &group.main=true - group.truncate(了解)
- 按照品牌分组展示相关的商品;
q=*:*&group=true&group.field=item_brand - 在次基础上使用facet,按照分类分组统计;统计的结果,基于q中的条件进行的facet分组。
q=*:*&group=true&group.field=item_brand &facet=true &facet.field=item_category - 如果我们想基于每个分组中匹配度高的文档进行Facet分组统计
q=*:*&group=true&group.field=item_brand &facet=true &facet.field=item_category &group.truncate=true
4.7 高级查询-高亮查询
4.7.1 高亮的概述
- 高亮显示是指根据关键字搜索文档的时候,显示的页面对关键字给定了特殊样式, 让它显示更加突出,如下面商品搜索中,关键字变成了红色,其实就是给定了红色样 ;
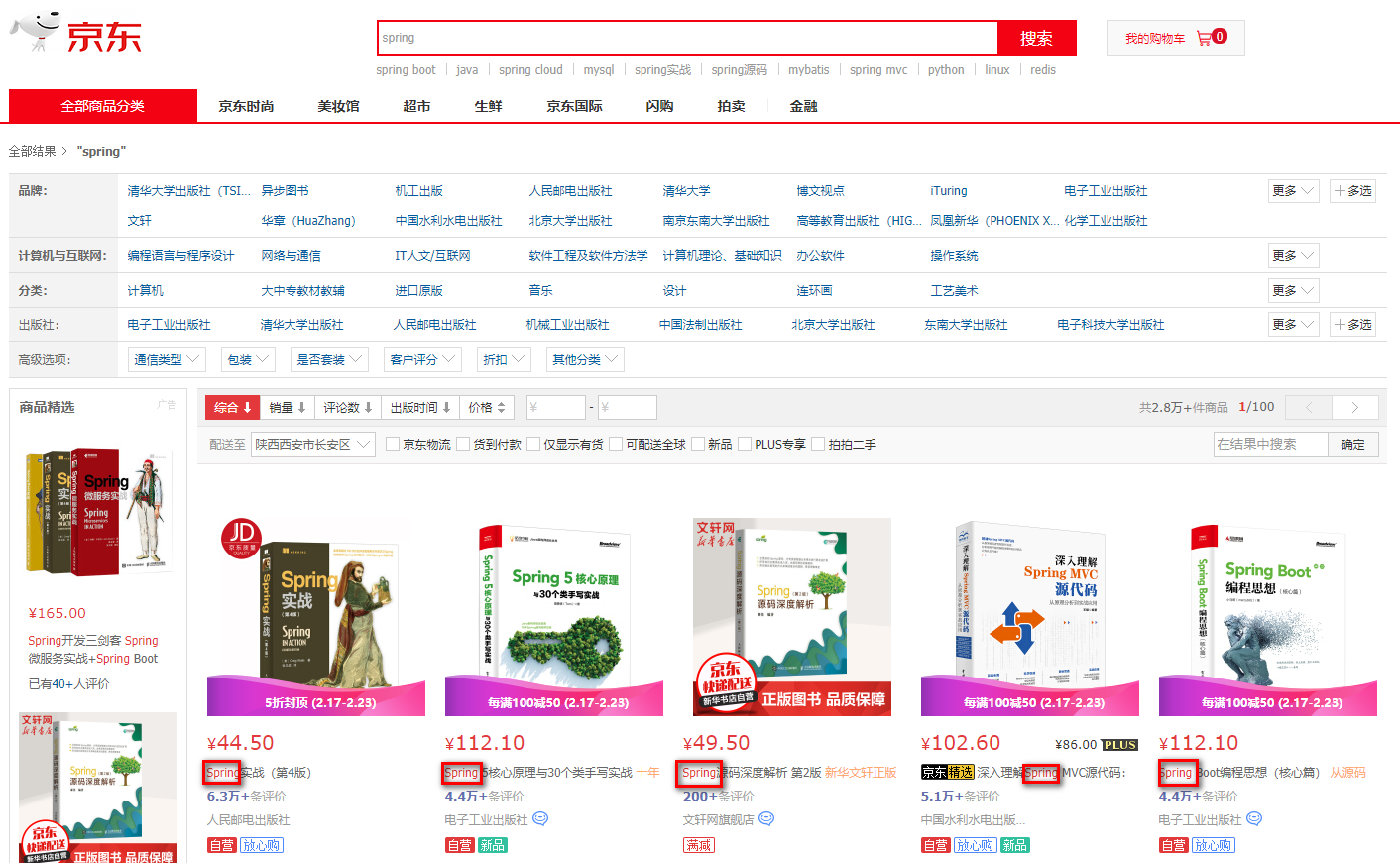
- 高亮的本质,是对域中包含关键字前后加标签
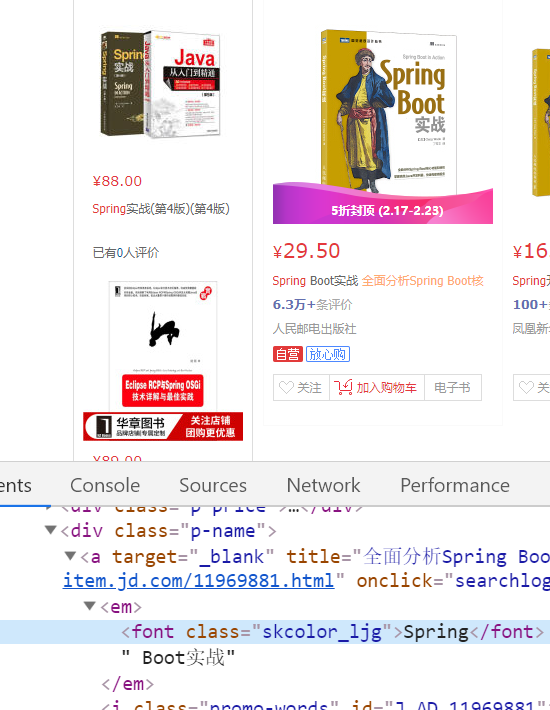
4.7.2 Solr高亮分类和高亮基本使用
上一节我们简单阐述了什么是高亮,接下来我们来讲解Solr中高亮的实现方案;
在Solr中提供了常用的3种高亮的组件(Highlighter)也称为高亮器,来支持高亮查询。
Unified Highlighter
- Unified Highlighter是最新的Highlighter(从Solr6.4开始),它是最性能最突出和最精确的选择。它可以通过插件/扩展来处理特定的需求和其他需求。官方建议使用该Highlighter,即使它不是默认值。
Original Highlighter
- Original Highlighter,有时被称为"Standard Highlighter" or "Default Highlighter",是Solr最初的Highlighter,提供了一些定制选项,曾经一度被选择。它的查询精度足以满足大多数需求,尽管它不如统一的Highlighter完美;
FastVector Highlighter
- FastVector Highlighter特别支持多色高亮显示,一个域中不同的词采用不同的html标签作为前后缀。
Highlighter公共的一些参数,先来认识一下其中重要的一些参数;
参数 值 描述 hl true|false 通过此参数值用来开启或者禁用高亮.默认值是false.如果你想使用高亮,必须设置成true hl.method unified|original|fastVector 使用哪种哪种高亮组件. 接收的值有: unified,original,fastVector. 默认值是original.hl.fl filed1,filed2... 指定高亮字段列表.多个字段之间以逗号或空格分开.表示那个字段要参与高亮。默认值为空字符串。 hl.q item_title:三星 高亮查询条件,此参数运行高亮的查询条件和q中的查询条件不同。如果你设置了它, 你需要设置 hl.qparser.默认值和q中的查询条件一致hl.tag.pre <em>高亮词开头添加的标签,可以是任意字符串,一般设置为HTML标签,默认值为 <em>.对于Original Highlighter需要指定hl.simple.prehl.tag.post </em>高亮词后面添加的标签,可以是任意字符串,一般设置为HTML标签,默认值 </em>.对于Original Highlighter需要指定hl.simple.posthl.qparser lucene|dismax|edismax 用于hl.q查询的查询解析器。仅当hl.q设置时适用。默认值是defType参数的值,而defType参数又默认为lucene。 hl.requireFieldMatch true|false 默认为fasle. 如果置为true,除非该字段的查询结果不为空才会被高亮。它的默认值是false,意味 着它可能匹配某个字段却高亮一个不同的字段。如果hl.fl使用了通配符,那么就要启用该参数 hl.usePhraseHighlighter true|false 默认true.如果一个查询中含有短语(引号框起来的)那么会保证一定要完全匹配短语的才会被高亮 hl.highlightMultiTerm true|false 默认true.如果设置为true,solr将会高亮出现在多terms查询中的短语。 hl.snippets 数值 默认为1.指定每个字段生成的高亮字段的最大数量. hl.fragsize 数值 每个snippet返回的最大字符数。默认是100.如果为0,那么该字段不会被fragmented且整个字段的值会被返回 hl.encoder html 如果为空(默认值),则存储的文本将返回,而不使用highlighter执行任何转义/编码。如果设置为html,则将对特殊的html/XML字符进行编码; hl.maxAnalyzedChars 数值 默认10000. 搜索高亮的最大字符,对一个大字段使用一个复杂的正则表达式是非常昂贵的。 高亮的入门案例:
- 查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
q=item_title:手机 &hl=true &hl.fl=item_title &hl.simple.pre=<font> &hl.simple.post=</font>

- 查询item_title中包含手机的文档,并且对item_title中的手机关键字进行高亮;
4.7.3 Solr高亮中其他的参数介绍
- [hl.fl]指定高亮的域,表示哪些域要参于高亮;
- 需求:查询Item_title:手机的文档, Item_title,item_category为高亮域
q=item_title:手机 &hl=true &hl.fl=item_title,item_category &hl.simple.pre=<font> &hl.simple.post=</font> - 结果中item_title手机产生了高亮,item_category中手机也产生了高亮.

- 这种高亮肯对我们来说是不合理的。可以使用hl.requireFieldMatch参数解决。
- [hl.requireFieldMatch]只有符合对应查询条件的域中参数才进行高亮;只有item_title手机才会高亮。
q=item_title:手机 &hl=true &hl.fl=item_title,item_category &hl.simple.pre=<font> &hl.simple.post=</font> &hl.requireFieldMatch=true
- [hl.q] 默认情况下高亮是基于q中的条件参数。 使用fl.q让高亮的条件参数和q的条件参数不一致。比较少见。但是solr提供了这种功能。
- 需求:查询Item_tile中包含三星的文档,对item_category为手机的进行高亮;
q=item_title:三星 &hl=true &hl.q=item_category:手机 &hl.fl=item_category &hl.simple.pre=<em> &hl.simple.post=</em>
- [hl.highlightMultiTerm]默认为true,如果为true,Solr将对通配符查询进行高亮。如果为false,则根本不会高亮显示它们。
q=item_title:micro* OR item_title:panda &hl=true &hl.fl=item_title &hl.simple.pre=<em> &hl.simple.post=</em>
- 对应基于通配符查询的结果不进行高亮;
q=item_title:micro* OR item_title:panda &hl=true &hl.fl=item_title &hl.simple.pre=<em> &hl.simple.post=</em> &hl.highlightMultiTerm=false - [hl.usePhraseHighlighter]为true时,将来我们基于短语进行搜索的时候,短语做为一个整体被高亮。为false时,短语中的每个单词都会被单独高亮。在Solr中短语需要用引号引起来;
q=item_title:"老人手机" &hl=true &hl.fl=item_title &hl.simple.pre=<font> &hl.simple.post=</font>
- 关闭hl.usePhraseHighlighter=false;
q=item_title:"老人手机" &hl=true &hl.fl=item_title &hl.simple.pre=<font> &hl.simple.post=</font> &hl.usePhraseHighlighter=false;
4.7.4 Highlighter的切换
- 之前我们已经讲解完毕Highlighter中的通用参数,所有Highlighter都有的。接下来我们要讲解的是Highlighter的切换和特有参数。
- 如何切换到unified (
hl.method=unified),切换完毕后,其实我们是看不出他和original有什么区别。因为unified Highlighter比original Highlighter只是性能提高。精确度提高。 - 区别不是很大,unified 相比original 的粒度更细;
q=item_title:三星平板电视 &hl=true &hl.fl=item_title &hl.simple.pre=<font> &hl.simple.post=</font> &hl.method=unified
- 如何切换到fastVector
- 优势:使用fastVector最大的好处,就是可以为域中不同的词使用不同的颜色,第一个词使用黄色,第二个使用红色。而且fastVector和orignal可以混合使用,不同的域使用不同的Highlighter;
- 使用fastVector的要求:使用FastVector Highlighter需要在高亮域上设置三个属性(termVectors、termPositions和termOffset);
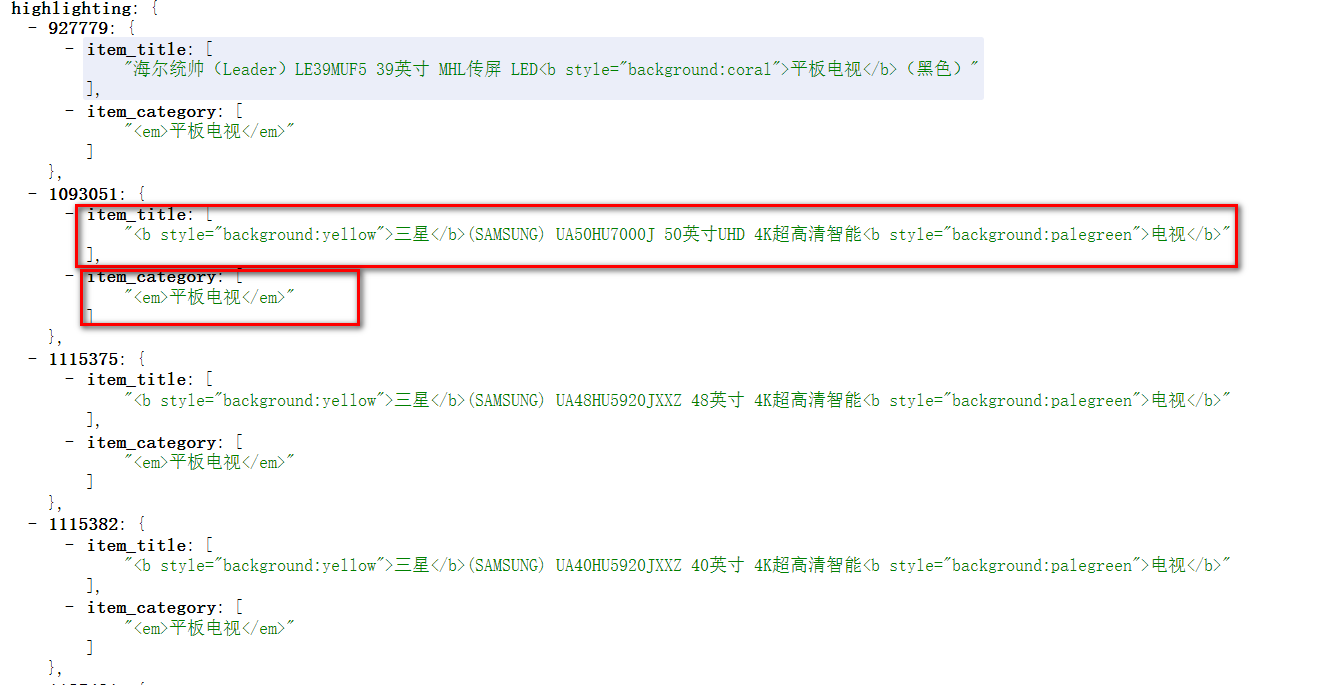
- 需求:查询item_title中包含三星平板电视,item_category是平板电视的文档。
- item_title中的高亮词要显示不同的颜色。xml
<field name="item_title" type="text_ik" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />xml<!-- 重启Solr,重写生成索引; --> <delete> <query>*:*</query> </delete> <commit/> - 修改solrcofig.xml配置文件指定fastVector高亮器的前后缀xml
<!-- 官方给的一个例子 --> <fragmentsBuilder name="colored" class="solr.highlight.ScoreOrderFragmentsBuilder"> <lst name="defaults"> <str name="hl.tag.pre"> <![CDATA[ <b style="background:yellow">,<b style="background:lawgreen">, <b style="background:aquamarine">,<b style="background:magenta">, <b style="background:palegreen">,<b style="background:coral">, <b style="background:wheat">,<b style="background:khaki">, <b style="background:lime">,<b style="background:deepskyblue">]]> </str> <str name="hl.tag.post"> <![CDATA[</b>]]> </str> </lst> </fragmentsBuilder> - 需要请求处理器中配置使用colored这一套fastVector的前后缀;xml
<str name="hl.fragmentsBuilder">colored</str>q=item_title:三星平板电视 AND item_category:平板电视 &hl=true &hl.fl=item_title,item_category &hl.method=original &f.item_title.hl.method=fastVector - 测试
- 到这关于Highlighter的切换我们就讲解完毕了。不同的Highlighter也有自己特有的参数,这些参数大多是性能参数。大家可以参考官方文档。 http://lucene.apache.org/solr/guide/8_1/highlighting.html#the-fastvector-highlighter
4.8 Solr Query Suggest
4.8.1 Solr Query Suggest简介
- Solr从1.4开始便提供了Query Suggest,Query Suggest目前是各大搜索应用的标配,主要作用是避免用户输入错误的搜索词,同时将用户引导到相应的关键词上进行搜索。Solr内置了Query Suggest的功能,它在Solr里叫做Suggest模块. 使用该模块.我们通常可以实现2种功能。拼写检查(Spell-Checking),再一个就是自动建议(AutoSuggest)。
- 什么是拼写检查(Spell-Checking)
- 比如说用户搜索的是sorl,搜索应用可能会提示你,你是不是想搜索solr.百度就有这个功能。
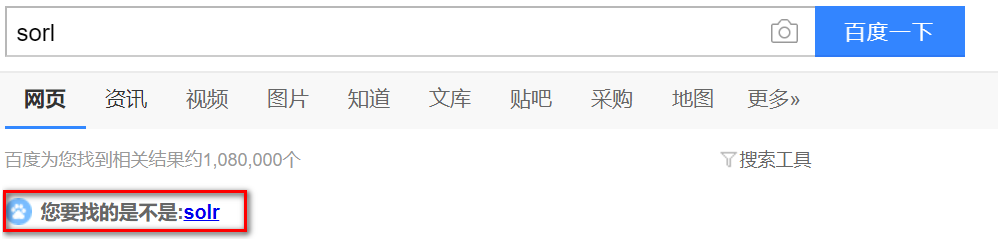
- 这就是拼写检查(Spell Checking)的功能。
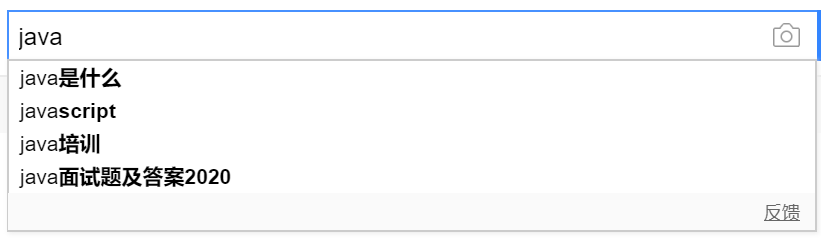
- 什么又是自动建议(AutoSuggest)
- AutoSuggest是指用户在搜索的时候,给用户一些提示建议,可以帮助用户快速构建自己的查询。
- 比如我们搜索java.
4.8.2 Spell-Checking的使用
- 要想使用Spell-Checking首先要做的事情,就是在SolrConfig.xml文件中配置SpellCheckComponent;并且要指定拼接检查器,Solr一共提供了4种拼写检查器IndexBasedSpellChecker,DirectSolrSpellChecker,FileBasedSpellChecker和WordBreakSolrSpellChecker。这4种拼写检查的组件,我们通常使用的都是第二种。
- IndexBasedSpellChecker(了解)
- IndexBasedSpellChecker 使用 Solr 索引作为拼写检查的基础。它要求定义一个域作为拼接检查term的基础域。
- 需求:对item_title域,item_brand域,item_category域进行拼接检查。
- 定义一个域作为拼接检查term 的基础域item_title_spell,将item_title,item_brand,item_category域复制到item_title_spell;
xml<field name="item_title_spell" type="text_ik" indexed="true" stored="false" multiValued="true" /> <copyField source="item_title" dest="item_title_spell" /> <copyField source="item_brand" dest="item_title_spell" /> <copyField source="item_category" dest="item_title_spell" />- 在SolrConfig.xml中配置IndexBasedSpellChecker作为拼写检查的组件
xml<searchComponent name="indexspellcheck" class="solr.SpellCheckComponent"> <lst name="spellchecker"> <str name="classname">solr.IndexBasedSpellChecker</str> <!--组件的实现类--> <str name="spellcheckIndexDir">./spellchecker</str> <!--拼写检查索引生成目录--> <str name="field">item_title_spell</str> <!--拼写检查的域--> <str name="buildOnCommit">true</str><!--是否每次提交文档的时候,都生成拼写检查的索引--> <!-- optional elements with defaults <str name="distanceMeasure">org.apache.lucene.search.spell.LevensteinDistance</str> <str name="accuracy">0.5</str> --> </lst> </searchComponent>- 在请求处理器中配置拼写检查的组件;
xml<arr name="last-components"> <str>indexspellcheck</str> </arr>q=item_title:meta &spellcheck=true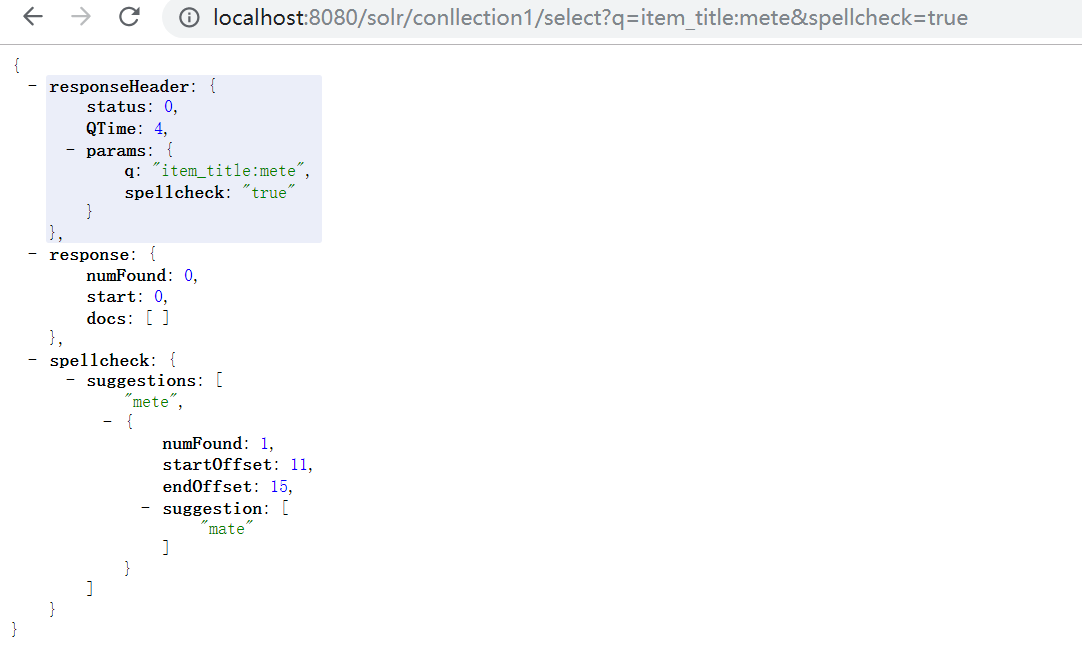
- DirectSolrSpellChecker
- 需求:基于item_title域,item_brand域,item_category域进行搜索的时候,需要进行拼接检查。
- 使用流程:
- 首先要定义一个词典域,拼写检查是需要根据错误词--->正确的词,正确的词构成的域;
- 由于我们在进行拼写检查的时候,可能会有中文,所以需要首先创建一个词典域的域类型。
xml<!-- 说明 这里spell 单独定义一个类型 是为了屏蔽搜索分词对中文拼写检测的影响,分词后查询结果过多不会给出建议词 --> <fieldType name="spell_text_ik" class="solr.TextField"> <analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" /> <analyzer type="query"> <tokenizer class="solr.WhitespaceTokenizerFactory" /> </analyzer> </fieldType>- 定义一个词典的域,将需要进行拼写检查的域复制到该域;
xml<field name="spell" type="spell_text_ik" multiValued="true" indexed="true" stored="false"/> <copyField source="item_title" dest="spell"/> <copyField source="item_brand" dest="spell"/> <copyField source="item_category" dest="spell"/>- 修改SolrConfig.xml中的配置文件中的拼写检查器组件。指定拼写词典域的类型,词典域
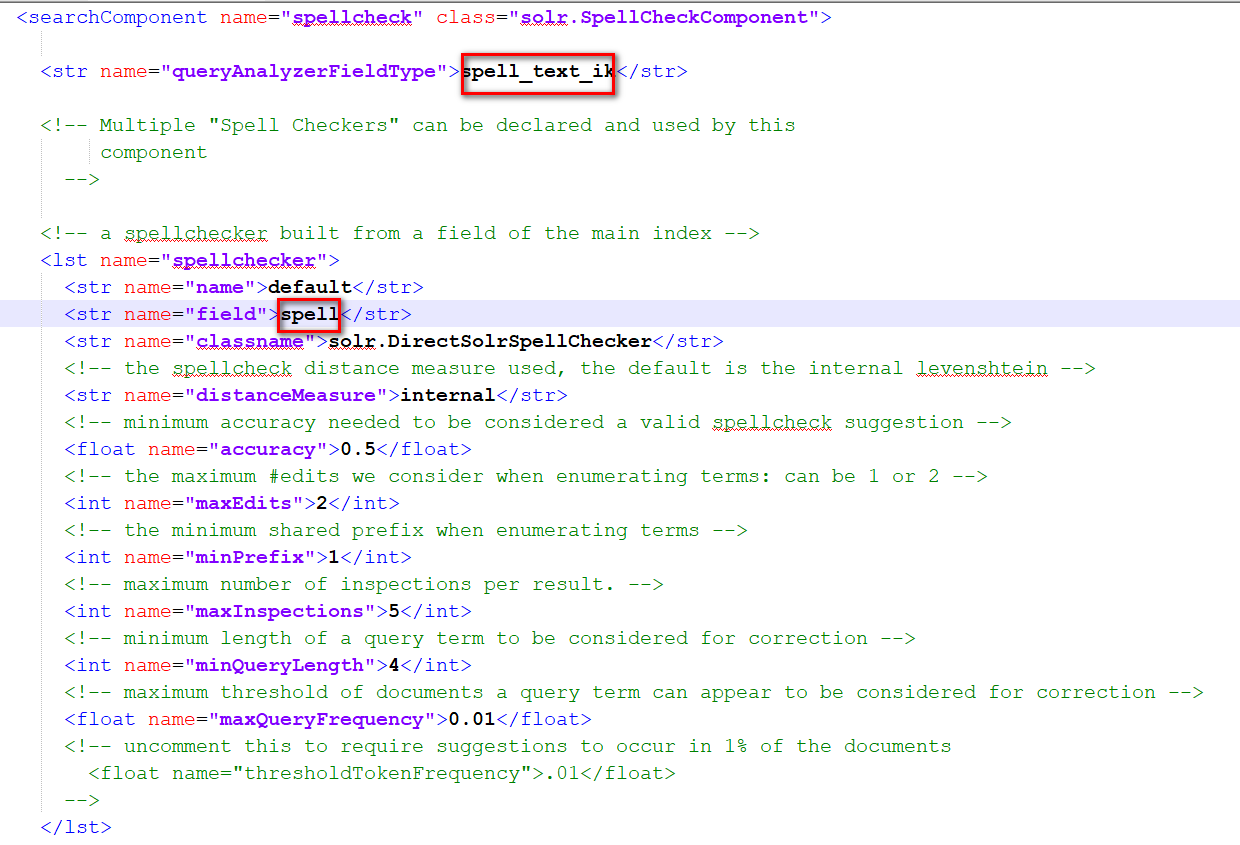
- 修改SolrConfig.xml中的配置文件中的拼写检查器组件。指定拼写词典域的类型,词典域
- 在Request Handler中配置拼写检查组件
xml<arr name="last-components"> <str>spellcheck</str> </arr>- 重启,重新创建索引。
- 测试,spellcheck=true参数表示是否开启拼写检查,搜索内容一定大于等于4个字符。
http://localhost:8080/solr/collection1/select?q=item_title:iphono&spellcheck=true http://localhost:8080/solr/collection1/select?q=item_title:galax&spellcheck=true http://localhost:8080/solr/collection1/select?q=item_brand:中国移走&spellcheck=true
- FileBasedSpellChecker
- 使用外部文件作为拼写检查字的词典,基于词典中的词进行拼写检查。
- 在solrconfig.xml中配置拼写检查的组件。
xml<searchComponent name="fileChecker" class="solr.SpellCheckComponent"> <lst name="spellchecker"> <str name="classname">solr.FileBasedSpellChecker</str> <str name="name">fileChecker</str> <str name="sourceLocation">spellings.txt</str> <str name="characterEncoding">UTF-8</str> <!-- optional elements with defaults--> <str name="distanceMeasure">org.apache.lucene.search.spell.LevensteinDistance</str> <!--精确度,介于0和1之间的值。值越大,匹配的结果数越少。假设对 helle进行拼写检查, 如果此值设置够小的话," hellcat","hello"都会被认为是"helle"的正确的拼写。如果此值设置够大,则"hello"会被认为是正确的拼写 --> <str name="accuracy">0.5</str> <!--表示最多有几个字母变动。比如:对"manag"进行拼写检查,则会找到"manager"做为正确的拼写检查;如果对"mana"进行拼写检查,因为"mana"到"manager",需有3个字母的变动,所以"manager"会被遗弃 --> <int name="maxEdits">2</int> <!-- 最小的前辍数。如设置为1,意思是指第一个字母不能错。比如:输入"cinner",虽然和"dinner"只有一个字母的编辑距离,但是变动的是第一个字母,所以"dinner"不是"cinner"的正确拼写 --> <int name="minPrefix">1</int> <!-- 进行拼写检查所需要的最小的字符数。此处设置为4,表示如果只输入了3个以下字符,则不会进行拼写检查(3个以下的字符用户基本) --> <int name="minQueryLength">4</int> <!-- 被推荐的词在文档中出现的最小频率。整数表示在文档中出现的次数,百分比数表示有百分之多少的文档出现了该推荐词--> <float name="maxQueryFrequency">0.01</float> </lst> </searchComponent>- 在SolrCore/conf目录下,创建一个拼写检查词典文件,该文件已经存在。
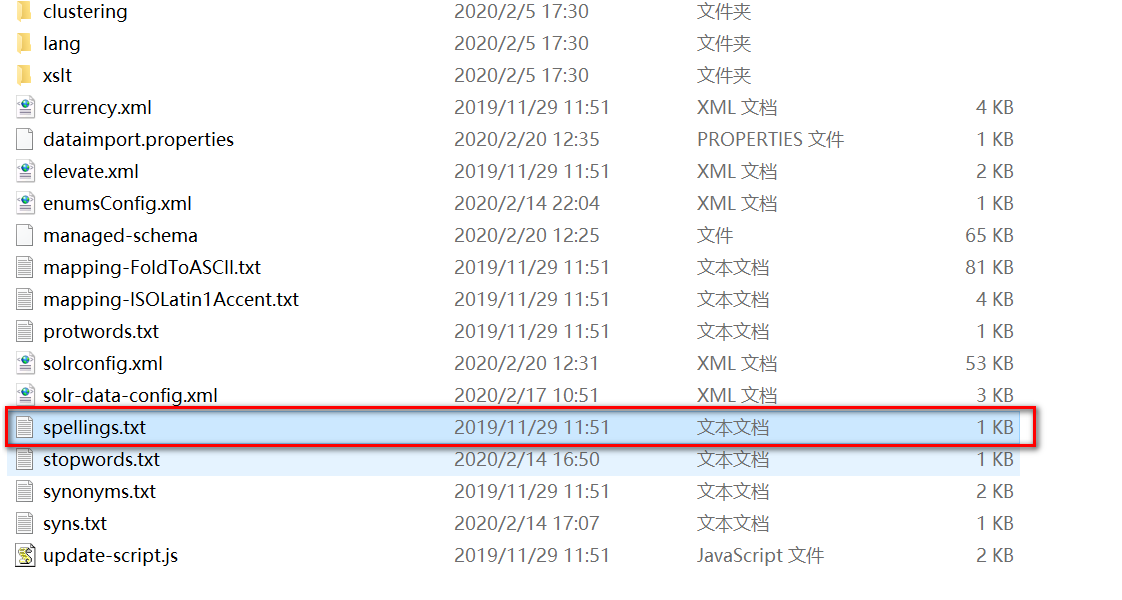
- 在SolrCore/conf目录下,创建一个拼写检查词典文件,该文件已经存在。
- 加入拼写检查的词;
pizza history 传智播客- 在请求处理器中配置拼写检查组件
xml<arr name="last-components"> <str>fileChecker</str> </arr>http://localhost:8080/solr/collection1/select?q=item_title:pizzaaa&spellcheck=true&spellcheck.dictionary=fileChecker&spellcheck.build=true
- WordBreakSolrSpellChecker
- WordBreakSolrSpellChecker可以通过组合相邻的查询词/或将查询词分解成多个词来提供建议。是对SpellCheckComponent增强,通常WordBreakSolrSpellChecker拼写检查器可以配合一个传统的检查器(即:DirectSolrSpellChecker)。xml
<lst name="spellchecker"> <str name="name">wordbreak</str> <str name="classname">solr.WordBreakSolrSpellChecker</str> <str name="field">sepll</str> <str name="combineWords">true</str> <str name="breakWords">true</str> <int name="maxChanges">10</int> </lst>http://localhost:8080/solr/collection1/select?q=item_title:iphone&spellcheck=true&spellcheck.dictionary=default&spellcheck.dictionary=wordbreak
- WordBreakSolrSpellChecker可以通过组合相邻的查询词/或将查询词分解成多个词来提供建议。是对SpellCheckComponent增强,通常WordBreakSolrSpellChecker拼写检查器可以配合一个传统的检查器(即:DirectSolrSpellChecker)。
4.8.3 拼写检查相关的参数
| 参数 | 值 | 描述 |
|---|---|---|
| spellcheck | true | false | 此参数为请求打开拼写检查建议。如果true,则会生成拼写建议。如果需要拼写检查,则这是必需的。 |
| spellcheck.build | true | false | 如果设置为true,则此参数将创建用于拼写检查的字典。在典型的搜索应用程序中,您需要在使用拼写检查之前构建字典。但是,并不总是需要先建立一个字典。例如,您可以将拼写检查器配置为使用已存在的字典。 |
| spellcheck.count | 数值 | 此参数指定拼写检查器应为某个术语返回的最大建议数。如果未设置此参数,则该值默认为1。如果参数已设置但未分配一个数字,则该值默认为5。如果参数设置为正整数,则该数字将成为拼写检查程序返回的建议的最大数量。 |
| spellcheck.dictionary | 指定要使用的拼写检查器 | 默认值defualt |
4.8.4 AutoSuggest 入门
- AutoSuggest 是搜索应用一个方便的功能,对用户输入的关键字进行预测和建议,减少了用户的输入。首先我们先来讲解一下suggest的入门流程;
- 在solrconfig.xml中配置suggsetComponent,并且要在组件中配置自动建议器,配置文件已经配置过。
xml<searchComponent name="suggest" class="solr.SuggestComponent"> <lst name="suggester"> <str name="name">mySuggester</str> 自动建议器名称,需要在查询的时候指定 <str name="lookupImpl">FuzzyLookupFactory</str> 查找器工厂类,确定如何从字典索引中查找词 <str name="dictionaryImpl">DocumentDictionaryFactory</str>决定如何将词存入到索引。 <str name="field">item_title</str> 词典域。一般指定查询的域/或者复制域。 <str name="weightField">item_price</str> <str name="suggestAnalyzerFieldType">text_ik</str> </lst> </searchComponent>- 修改组件参数
- 在请求处理器中配置suggest组件,sugges名称要和SearchComponent的name一致。
xml<arr name="components"> <str>suggest</str> </arr> <!-- 补充:在solrConfig.xml中已经定义了一个请求处理器,并且已经配置了查询建议组件 --> <requestHandler name="/suggest" class="solr.SearchHandler" startup="lazy"> <lst name="defaults"> <str name="suggest">true</str> <str name="suggest.count">10</str> </lst> <arr name="components"> <str>suggest</str> </arr> </requestHandler>- 执行查询,指定suggest参数
http://localhost:8080/solr/collection1/suggest?q=三星http://localhost:8080/solr/collection1/select?q=三星&suggest=true&suggest.dictionary=mySuggester- 结果
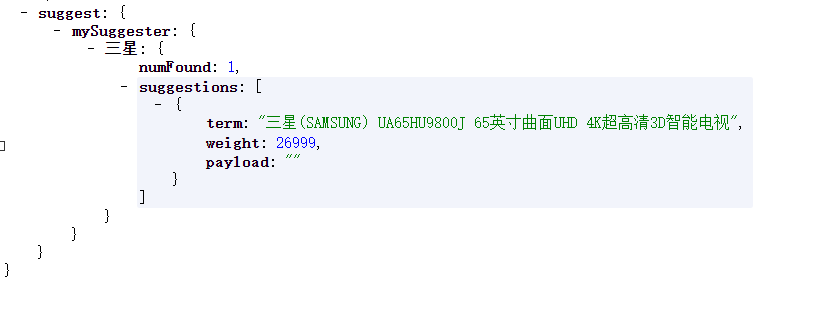
- 结果
4.8.5 AutoSuggest中相关的参数。
<searchComponent name="suggest" class="solr.SuggestComponent">
<lst name="suggester">
<!-- 自动建议器名称,需要在查询的时候指定 -->
<str name="name">mySuggester</str>
<!-- 表示自动建议的内容是基于哪个域的 -->
<str name="field">item_title</str>
<!-- 词典实现类,表示分词(Term)是如何存储Suggestion字典的。 DocumentDictionaryFactory一个基于词,权重,创建词典; -->
<str name="dictionaryImpl">DocumentDictionaryFactory</str>
<!-- 查询实现类,表示如何在Suggestion词典中找到分词(Term) -->
<str name="lookupImpl">FuzzyLookupFactory</str>
<!-- 权重域。 -->
<str name="weightField">item_price</str>
<!-- 域类型 -->
<str name="suggestAnalyzerFieldType">text_ik</str>
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>4.8.6 AutoSuggest查询相关参数
http://localhost:8080/solr/collection1/select?q=三星&suggest=true&suggest.dictionary=mySuggester
| 参数 | 值 | 描述 |
|---|---|---|
| suggest | true|false | 是否开启suggest |
| suggest.dictionary | 字符串 | 指定使用的suggest器名称 |
| suggest.count | 数值 | 默认值是1 |
| suggest.build | true|false | 如果设置为true,这个请求会导致重建suggest索引。这个字段一般用于初始化的操作中,在线上环境,一般不会每个请求都重建索引,如果线上你希望保持字典最新,最好使用buildOnCommit或者buildOnOptimize来操作。 |